|
编码方式的简介 1. ASCII ASCII是7比特的字符集,涵盖了英语中的绝大多数字符。编码从0到127. 2. ISOLatin-1(the ISO-8859-1 standard) ISO Latin-1是8比特的字符集,定义了256个字符。前128个字符(00000000-01111111)与ASCII完全一致。
3. Unicode Unicode只是定义了字符的编码值,并未指定值以何种形式存储。比如汉字“田”的Unicode编码是7530,转换为二进制是01110101,00110000。比方现在定义一种unicode的实现方式UTF-FAKE,规则是 a. 使用24个字节 b. 每个字节的高7位都是1 c. 每个字节的最末一位存储unicode编码值 那么01110101,00110000的存储形式是 11111110, 11111110, 11111110, 11111110, 11111110, 11111110, 11111110, 11111110, 11111110, 11111111, 11111111, 11111111, 11111110, 11111111, 11111110, 11111111, 11111110, 11111110, 11111111, 11111111, 11111110, 11111110, 11111110, 11111110 其中末位为蓝色0的字节为补足字节。 实际使用的编码方式UTF-8使用三个字节存储“田” 01110101,00110000,如下 11100111, 10010100, 10110000
Unicode的第一个版本于1991年发布,该版本允许的的最大编码空间是两个字节。96年发布的Unicode 2.0版本引入了surrogate pair,将Unicode的编码数目扩充到了百万级,由于可见的将来该数目不大可能用光,因此Unicode委员会对外宣称该上限永不会更改。Surrogate pair在UTF-16和UTF-32中得到了实现。Unicode的前256个字符及编码值与Latin-1完全一致。比如大写字母A在Latin-1和Unicode中的编码值都是0x41(十进制的65)。 Unicode的编码值范围是 000000hex 到10FFFFhex,可划分为17个plane,每个plane包含65536(= 216)个字符。Plane的代码从0到16(十进制),对应于 000000hex,010000hex,020000hex,… … ,0F0000hex,10FFFFhex的蓝色部分。 Unicode的表示方式一般是”U ”后缀上4到6个十六进制字符,如”田“的Unicode表示方式是U 7530。
4. UTF-8 UTF-8采用可变长度的编码,长度从1到4个字节不等。某些应用识别非标准的'utf8' 或'UTF 8'别名。只有ASCII字符在UTF-8中使用一个字节编码,且值与ASCII完全相同,其余字符在UTF-8中使用2到4个字节。因此UTF-8中的单字节且只有单字节编码字符的最高的1个比特是0。 UTF-8对Unicode字符的编码规则如下
说明如下: 1. 只有ASCII使用单字节编码 2. Unicode编码值大于127的字符使用多个字节编码。多字节序列的第一个字节称为leading byte,后续的字节称为continuation bytes。Leading byte的高位是110,1110或11110,其中的“1”的个数标明了序列中的字节总数。如2个字节序列的leading byte为 3. 单字节序列、leading bytes和continuationbytes的高位分别是0,110/1110/11110和10,因此不会混淆。 还是以汉字”田“为例,展示Unicode字符如何按照UTF-8存储。”田“的Unicode值是U 7530,比对上表发现介于U 0800 - U FFFF之间,因此需要3个字节来存储。7530转为二进制是1110101,00110000,一共15位。但由于UTF-8的3字节编码存储16个比特,因此将1110101,00110000的高一位补零变成16比特01110101,00110000。然后将这16比特依次填入三字节序列1110xxxx 10xxxxxx 10xxxxxx的x中,得到结果 11100111 10010100 10110000,写成16进制就是E7 94 B0 注意:虽然Unicode中的前256个字符及编码值与Latin-1完全一致,但UTF-8只对前128个即ASCII字符采用单字节编码,其余128个Latin-1字符是采用2个字节编码。因此ASCII编码的文件可以直接以UTF-8方式读取,而Latin-1的文件若包含值为128-255的字符则不可以。 5. UTF-16 UTF-16也是采用可变长度编码,可以是一个或者两个16比特。某些应用中允许使用非标准的UTF_16或者UTF16作为别名。Unicode中的第一个plane的65536(= 216)codepoints采用16比特编码,其余的16个plane均采用2个16比特编码。采用2个16比特编码的前后两个16bit分别称为lead surrogate pair和trail surrogate pair,之所以称为surrogate是因为单独一个16bit不代表任何字符,只有组合起来才有意义。 既然UTF-16也是可变长度编码,如何区分某个16bit是单独表示一个字符还是与后续的16bit组合起来表示一个字符呢?Unicode将D800–DBFF和DC00–DFFF这两个范围作为保留区间,没有将之分配给任何Unicode字符,若某16比特落在D800–DBFF范围内,便可将之视为采用2个16bit编码字符的第一个16bit,而落在DC00–DFFF的16bit可视为采用2个16bit编码字符的第二个16bit。这就使得Unicode第一个plane实际可分配使用的code points只有65536 – (DFFF - D800 1) = 65536 – 8*256 = 63488。 采用一个16bit编码的Unicode字符在UTF-16中的编码值与其在Unicode中是相等的,比如英文大写字母A的Unicode值是U 0041,其UTF-16编码是0041 hex 。Unicode第二到第十七个plane采用两个16bit即surrogate pairs的字符从其Unicode code point到UTF-16的转换规则是 1. 范围为0x10000 … 0x10FFFF的codepoint减去0x010000,减过后的结果范围是0x00000到0xFFFFF,使得该结果可以使用5位16进制亦即20位2进制数表示 2. 结果中高10位(范围是0x0到0x3FF)加上0xD800(结果范围是0xD800到0xDBFF)作为双16bit的第一个16bit即leadsurrogate 3. 结果中低10位(范围是0x0到0x3FF)加上0xDC00(结果范围是0xDC00到0xDFFF)作为双16bit的第二个16bit即trailsurrogate
这样UTF-16与UTF-8都是self-synchronizing的,即某个16bit是否是一个字符的开始无需检查其前一个或者后一个16bit。与UTF-8的不同之处是,UTF-16不支持从某个随机的字节开始读取。 举例:UTF-16 序列 0041, D801DC01 (字符'A BOM(byte-order mark) BOM是Unicode中用来标识字节顺序的字符。 对于UTF16和UTF32,由于编码单元分别是16bit和32bit,即2个和4个字节,编码单元内字节的顺序就取决于计算机的体系结构。以英文大写字母A和汉字田为例,大端(big endianness,缩写为BE)和小端(littleendianness,缩写为LE)存储的字节序列是
BOM就是用来标识编码使用的是大端还是小端存储,该符号位于文本序列起始字节之前。
UTF-8 UTF-8中的BOM是 0xEF,0xBB,0xBF。Unicode标准里面允许UTF-8使用BOM,但并不要求也不鼓励使用。由于UTF8编码单位是字节,字节的先后顺序在编码、传输和解码过程中均不改变,因此不存在endianness。BOM在UTF8中的唯一作用是标识序列使用的是UTF8编码,在由其它使用BOM的编码转换为UTF8编码的情况下,建议在UTF8序列中保留BOM以便转换回原编码的时候不丢失BOM信息。
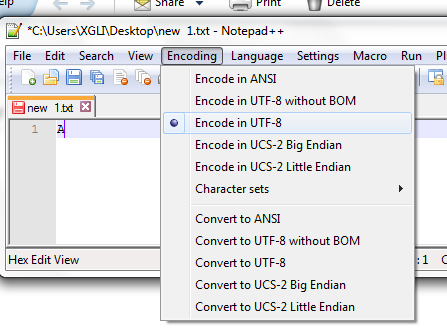
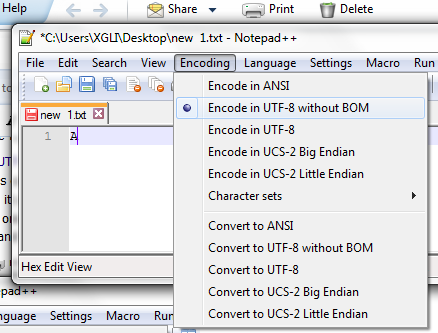
接下来看看用Notepad 的HEX-Editor插件查看的文件16进制的编码。 文件中仅包含一个英文大写字母A,其Unicode编码值是U 0041。 使用UTF-8(缺省包含BOM),字节序列是ef bb bf 41
使用不带BOM的UTF-8,字节序列是 41。
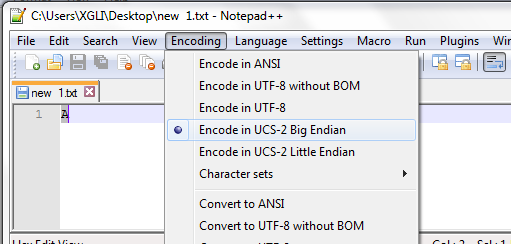
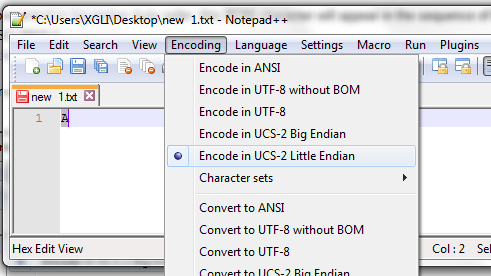
UTF-16UTF-16中bigendianness和littleendianness的BOM分别是U FEFF和U FFFE。可以使用编码方式UTF-16BE和UTF-16LE来显式地标明字节顺序,当使用了UTF-16BE和UTF-16LE时,BOM不应该再出现在字节序列中,很多应用直接忽略该字符若其仍然存在。 由于Notepad 不支持UTF16编码,因此下面的截图中使用了UTF-16的前身UCS-2来替代。UCS-2对Unicode的第一个plane的编码与UTF-16相同,都是1个16bit,且编码结果相同。
UTF-32 UTF32中的bigendianness和littleendianness的BOM分别是0000FEFF和FFFE0000。 总结五种编码方式的BOM依次是
|
|
|
来自: liang1234_ > 《关于编码》





 '),若第一个字节丢失即从第二个字节读取,那么UTF-16认为序列是41D8,01DC,01;而UTF-8不存在这个问题。
'),若第一个字节丢失即从第二个字节读取,那么UTF-16认为序列是41D8,01DC,01;而UTF-8不存在这个问题。