PE(Portable Executable)格式,是微软Win32环境可移植可执行文件(如exe、dll、vxd、sys和vdm等)的标准文件格式。PE格式衍生于早期建立在VAX(R)VMS(R)上的COFF(Common Object File Format)文件格式。
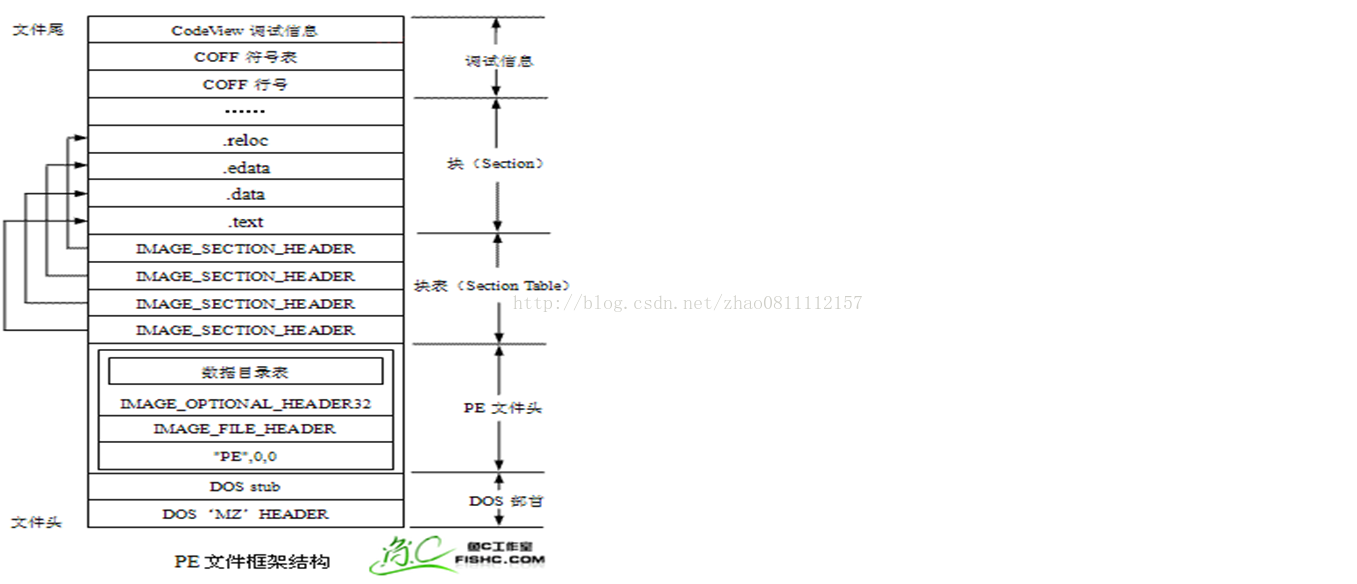
上面是 windows PE 可执行文件格式的结构图,分为 4 个部分:DOS 文件头、NT 文件头、Section 表以及 Directory 表格。
windows 的 executable image 文件使用的是这种 PE 格式,而 object 文件使用的是 COFF 文件格式。 | 种类 |
主扩展名 |
|---|
| 可执行系列 |
EXE / SCR |
| 库系列 |
DLL / OCX / CPL / DRV |
| 驱动程序系列 |
SYS / VXD |
| 对象文件序列 |
OBJ |
OBJ(对象)文件之外的所有文件都是可执行文件,DLL / SYS 文件等虽然不能直接在Shell(Explorer.exe)中运行,但可以使用其它方法执行. VA & RVA
VA指的是进程虚拟内存的绝对地址,RVA(Relative Virtual Address,相对虚拟地址)指从某个基准位置(ImageBase)开始的相对地址.VA 与 RVA 满足下面的换算关系.
RVA + ImageBase = VA
PE头内部信息大多以RVA形式存在.原因在于,PE文件(主要是DLL)加载到进程虚拟内存的特定位置时,该位置可能已经加载了其他PE文件(DLL).此时必须通过重定位(Relocation)将其加载到其他空白的位置,若PE头信息使用的是VA,则无法正常访问,因此使用RVA来定位信息,即是发生了重定位,只要相对于基准位置的相对地址没有变化,就能正常访问到指定信息,不会出现任何问题.
IMAGE_DOS_HEADER STRUCT
{
+00h WORD e_magic // Magic DOS signature MZ(4Dh 5Ah) DOS可执行文件标记
+02h WORD e_cblp // Bytes on last page of file
+04h WORD e_cp // Pages in file
+06h WORD e_crlc // Relocations
+08h WORD e_cparhdr // Size of header in paragraphs
+0ah WORD e_minalloc // Minimun extra paragraphs needs
+0ch WORD e_maxalloc // Maximun extra paragraphs needs
+0eh WORD e_ss // intial(relative)SS value DOS代码的初始化堆栈SS
+10h WORD e_sp // intial SP value DOS代码的初始化堆栈指针SP
+12h WORD e_csum // Checksum
+14h WORD e_ip // intial IP value DOS代码的初始化指令入口[指针IP]
+16h WORD e_cs // intial(relative)CS value DOS代码的初始堆栈入口
+18h WORD e_lfarlc // File Address of relocation table
+1ah WORD e_ovno // Overlay number
+1ch WORD e_res[4] // Reserved words
+24h WORD e_oemid // OEM identifier(for e_oeminfo)
+26h WORD e_oeminfo // OEM information;e_oemid specific
+29h WORD e_res2[10] // Reserved words
+3ch LONG e_lfanew // Offset to start of PE header 指向PE文件头
} IMAGE_DOS_HEADER ENDS
该结构有两个重要的成员
DWORD e_magic和LONG e_lfanew。DWORD e_magic为"MZ",定义为IMAGE_DOS_SIGNATURE。LONG e_lfanew存放PE头的文件偏移量。
#define IMAGE_DOS_SIGNATURE 0x4D5A // MZ
#define IMAGE_OS2_SIGNATURE 0x4E45 // NE
#define IMAGE_OS2_SIGNATURE_LE 0x4C45 // LE
#define IMAGE_NT_SIGNATURE 0x50450000 // PE00
②:DOS Stub【大约100个字节左右<此处字节数可选>】
它是一个总是由大约100个字节所组成的和MS-DOS 2.0兼容的可执行体,用来输出象
“this program needs windows NT”之类的错误信息。win32系统都直接跳过DOS Stub定
位到PE头。
③:typedef struct _IMAGE_NT_HEADERS 【PE文件头 共248字节】
{
+00 h DWORD Signature // PE标识头PE(50h 45h),共4字节
+04 h IMAGE_FILE_HEADER FileHeader // 结构体一,PE头共20个字节
+18 h IMAGE_OPTIONAL_HEADER32 OptionalHeader // 结构体二,PE文件共224字节
} IMAGE_NT_HEADERS ENDS, *PIMAGE_NT_HEADERS32;
Signature 字段:
在一个有效的 PE 文件里,Signature 字段被设置为00004550h, ASCII 码字符是“PE00”。标志这 PE 文件头的开始。“PE00” 字符串是 PE 文件头的开始,DOS 头部的 e_lfanew 字段正是指向这里

结构体一:typedef struct _IMAGE_FILE_HEADER 【PE头共20个字节】
{
+04h WORD Machine; // 运行平台
+06h WORD NumberOfSections; // 文件的区块数目
+08h DWORD TimeDateStamp; // 文件创建日期和时间
+0Ch DWORD PointerToSymbolTable; // 指向COFF符号表(主要用于调试)
+10h DWORD NumberOfSymbols; // COFF符号表中符号个数(同上)
+14h WORD SizeOfOptionalHeader; // IMAGE_OPTIONAL_HEADER32 结构大小
+16h WORD Characteristics; // 文件属性 } IMAGE_FILE_HEADER, *PIMAGE_FILE_HEADER;
(1)Machine:可执行文件的目标CPU类型。
| Value |
Meaning |
|---|
- IMAGE_FILE_MACHINE_I386
- 0x014c
|
x86
|
- IMAGE_FILE_MACHINE_IA64
- 0x0200
|
Intel Itanium
|
- IMAGE_FILE_MACHINE_AMD64
- 0x8664
|
x64
|
(2)NumberOfSection: 区块的数目。(注:区块表是紧跟在 IMAGE_NT_HEADERS 后边的)
(3)TimeDataStamp: 表明文件是何时被创建的。
这个值是自1970年1月1日以来用格林威治时间(GMT)计算的秒数,这个值是比文件系统(FILESYSTEM)的日期时间更加精确的指示器。
提示:VC的话可以用_ctime 函数或者 gmtime 函数。
(4)PointerToSymbolTable: COFF 符号表的文件偏移位置,现在基本没用了。
(5)NumberOfSymbols: 如果有COFF 符号表,它代表其中的符号数目,COFF符号是一个大小固定的结构,如果想找到COFF 符号表的结束位置,则需要这个变量。
(6)SizeOfOptionalHeader: 紧跟着IMAGE_FILE_HEADER 后边的数据结构(IMAGE_OPTIONAL_HEADER)的大小。(对于32位PE文件,这个值通常是00E0h;对于64位PE32+文件,这个值是00F0h )。
(7)Characteristics: 文件属性,有选择的通过几个值可以运算得到。( 这些标志的有效值是定义于 winnt.h 内的 IMAGE_FILE_** 的值,具体含义见下表。普通的EXE文件这个字段的值一般是 0100h,DLL文件这个字段的值一般是 210Eh。)小甲鱼温馨提示:多种属性可以通过 “或运算” 使得同时拥有!
| Value |
Meaning |
|---|
- IMAGE_FILE_RELOCS_STRIPPED
- 0x0001
|
Relocation information was stripped from the file. The file must be
loaded at its preferred base address. If the base address is not
available, the loader reports an error.
|
- IMAGE_FILE_EXECUTABLE_IMAGE
- 0x0002
|
The file is executable (there are no unresolved external references).
|
- IMAGE_FILE_LINE_NUMS_STRIPPED
- 0x0004
|
COFF line numbers were stripped from the file.
|
- IMAGE_FILE_LOCAL_SYMS_STRIPPED
- 0x0008
|
COFF symbol table entries were stripped from file.
|
- IMAGE_FILE_AGGRESIVE_WS_TRIM
- 0x0010
|
Aggressively trim the working set. This value is obsolete.
|
- IMAGE_FILE_LARGE_ADDRESS_AWARE
- 0x0020
|
The application can handle addresses larger than 2 GB.
|
- IMAGE_FILE_BYTES_REVERSED_LO
- 0x0080
|
The bytes of the word are reversed. This flag is obsolete.
|
- IMAGE_FILE_32BIT_MACHINE
- 0x0100
|
The computer supports 32-bit words.
|
- IMAGE_FILE_DEBUG_STRIPPED
- 0x0200
|
Debugging information was removed and stored separately in another file.
|
- IMAGE_FILE_REMOVABLE_RUN_FROM_SWAP
- 0x0400
|
If the image is on removable media, copy it to and run it from the swap file.
|
- IMAGE_FILE_NET_RUN_FROM_SWAP
- 0x0800
|
If the image is on the network, copy it to and run it from the swap file.
|
- IMAGE_FILE_SYSTEM
- 0x1000
|
The image is a system file.
|
- IMAGE_FILE_DLL
- 0x2000
|
The image is a DLL file. While it is an executable file, it cannot be run directly.
|
- IMAGE_FILE_UP_SYSTEM_ONLY
- 0x4000
|
The file should be run only on a uniprocessor computer.
|
- IMAGE_FILE_BYTES_REVERSED_HI
- 0x8000
|
The bytes of the word are reversed. This flag is obsolete.
|
结构体二:typedef struct _IMAGE_OPTIONAL_HEADER【PE文件共224字节,其中数据目录表占128字节】
{
//
// Standard fields.
//
+18h WORD Magic; // 标志字, ROM 映像(0107h),普通可执行文件(010Bh)
+1Ah BYTE MajorLinkerVersion; // 链接程序的主版本号
+1Bh BYTE MinorLinkerVersion; // 链接程序的次版本号
+1Ch DWORD SizeOfCode; // 所有含代码的节的总大小
+20h DWORD SizeOfInitializedData; // 所有含已初始化数据的节的总大小
+24h DWORD SizeOfUninitializedData; // 所有含未初始化数据的节的大小
+28h DWORD AddressOfEntryPoint; // 程序执行入口RVA
+2Ch DWORD BaseOfCode; // 代码的区块的起始RVA
+30h DWORD BaseOfData; // 数据的区块的起始RVA
//
// NT additional fields. 以下是属于NT结构增加的领域。
//
+34h DWORD ImageBase; // 程序的首选装载地址
+38h DWORD SectionAlignment; // 内存中的区块的对齐大小
+3Ch DWORD FileAlignment; // 文件中的区块的对齐大小
+40h WORD MajorOperatingSystemVersion; // 要求操作系统最低版本号的主版本号
+42h WORD MinorOperatingSystemVersion; // 要求操作系统最低版本号的副版本号
+44h WORD MajorImageVersion; // 可运行于操作系统的主版本号
+46h WORD MinorImageVersion; // 可运行于操作系统的次版本号
+48h WORD MajorSubsystemVersion; // 要求最低子系统版本的主版本号
+4Ah WORD MinorSubsystemVersion; // 要求最低子系统版本的次版本号
+4Ch DWORD Win32VersionValue; // 莫须有字段,不被病毒利用的话一般为0
+50h DWORD SizeOfImage; // 映像装入内存后的总尺寸
+54h DWORD SizeOfHeaders; // 所有头 + 区块表的尺寸大小
+58h DWORD CheckSum; // 映像的校检和
+5Ch WORD Subsystem; // 可执行文件期望的子系统
+5Eh WORD DllCharacteristics; // DllMain()函数何时被调用,默认为 0
+60h DWORD SizeOfStackReserve; // 初始化时的栈大小
+64h DWORD SizeOfStackCommit; // 初始化时实际提交的栈大小
+68h DWORD SizeOfHeapReserve; // 初始化时保留的堆大小
+6Ch DWORD SizeOfHeapCommit; // 初始化时实际提交的堆大小
+70h DWORD LoaderFlags; // 与调试有关,默认为 0
+74h DWORD NumberOfRvaAndSizes; // 下边数据目录的项数,Windows NT 发布是16
+78h IMAGE_DATA_DIRECTORY DataDirectory[IMAGE_NUMBEROF_DIRECTORY_ENTRIES];
// 数据目录表【共占128字节16个子参数】;结构体一 } IMAGE_OPTIONAL_HEADER32, *PIMAGE_OPTIONAL_HEADER32;
●AddressOfEntryPoint字段
指出文件被执行时的入口地址,这是一个RVA地址(RVA的含义在下一节中详细介绍)。如果在一个可执行文件上附加了一段代码并想让这段代码首先被执行,那么只需要将这个入口地址指向附加的代码就可以了。
●ImageBase字段
指出文件的优先装入地址。也就是说当文件被执行时,如果可能的话,Windows优先将文件装入到由ImageBase字段指定的地址中,只有指定的地址已经被**模块使用时,文件才被装入到**地址中。链接器产生可执行文件的时候对应这个地址来生成机器码,所以当文件被装入这个地址时不需要进行重定位操作,装入的速度最快,如果文件被装载到**地址的话,将不得不进行重定位操作,这样就要慢一点。
对于EXE文件来说,由于每个文件总是使用独立的虚拟地址空间,优先装入地址不可能被**模块占据,所以EXE总是能够按照这个地址装入,这也意味着EXE文件不再需要重定位信息。对于DLL文件来说,由于多个DLL文件全部使用宿主EXE文件的地址空间,不能保证优先装入地址没有被**的DLL使用,所以DLL文件中必须包含重定位信息以防万一。因此,在前面介绍的
IMAGE_FILE_HEADER 结构的 Characteristics 字段中,DLL 文件对应的
IMAGE_FILE_RELOCS_STRIPPED 位总是为0,而EXE文件的这个标志位总是为1。
在链接的时候,可以通过对link.exe指定/base:address选项来自定义优先装入地址,如果不指定这个选项的话,一般EXE文件的默认优先装入地址被定为00400000h,而DLL文件的默认优先装入地址被定为10000000h。
●SectionAlignment 字段和 FileAlignment字段
SectionAlignment字段指定了节被装入内存后的对齐单位。也就是说,每个节被装入的地址必定是本字段指定数值的整数倍。而FileAlignment字段指定了节存储在磁盘文件中时的对齐单位。
●Subsystem字段
指定使用界面的子系统,它的取值如表17.3所示。这个字段决定了系统如何为程序建立初始的界面,链接时的/subsystem:**选项指定的就是这个字段的值,在前面章节的编程中我们早已知道:如果将子系统指定为Windows
CUI,那么系统会自动为程序建立一个控制台窗口,而指定为Windows GUI的话,窗口必须由程序自己建立。
界面子系统的取值和含义
|
取 值
|
Windows.inc中的预定义值
|
含 义
|
|
0
|
IMAGE_SUBSYSTEM_UNKNOWN
|
未知的子系统
|
|
1
|
IMAGE_SUBSYSTEM_NATIVE
|
不需要子系统(如驱动程序)
|
|
2
|
IMAGE_SUBSYSTEM_WINDOWS_GUI
|
Windows图形界面
|
|
3
|
IMAGE_SUBSYSTEM_WINDOWS_CUI
|
Windows控制台界面
|
|
5
|
IMAGE_SUBSYSTEM_OS2_CUI
|
OS2控制台界面
|
|
7
|
IMAGE_SUBSYSTEM_POSIX_CUI
|
POSIX控制台界面
|
|
8
|
IMAGE_SUBSYSTEM_NATIVE_WINDOWS
|
不需要子系统
|
|
9
|
IMAGE_SUBSYSTEM_WINDOWS_CE_GUI
|
Windows CE图形界面
|
●DataDirectory字段
这个字段可以说是最重要的字段之一,它由16个相同的
IMAGE_DATA_DIRECTORY结构组成,虽然PE文件中的数据是按照装入内存后的页属性归类而被放在不同的节中的,但是这些处于各个节中的数据按照用途可以被分为导出表、导入表、资源、重定位表等数据块,这16个IMAGE_DATA_DIRECTORY结构就是用来定义多种不同用途的数据块的(如表17.4所示)。IMAGE_DATA_DIRECTORY结构的定义很简单,它仅仅指出了某种数据块的位置和长度。
IMAGE_DATA_DIRECTORY STRUCT
VirtualAddress DWORD ? ; //数据的起始RVA
isize DWORD ? ; //数据块的长度
IMAGE_DATA_DIRECTORY ENDS

在
PE文件中寻找特定的数据时就是从这些IMAGE_DATA_DIRECTORY结构开始的,比如要存取资源,那么必须从第3个
IMAGE_DATA_DIRECTORY结构(索引为2)中得到资源数据块的大小和位置;同理,如果要查看PE文件导入了哪些DLL文件的哪些API函数,那就必须首先从第2个IMAGE_DATA_DIRECTORY结构得到导入表的位置和大小 结构体一:typedef struct _IMAGE_DATA_DIRECTORY 【共占8字节】
{
+00 h DWORD VirtualAddress; //数据的RVA
+04 h DWORD Size; //数据的大小
}IMAGE_DATA_DIRECTORY,*PIMAGE_DATA_DIRECTORY;
④:typedef struct _IMAGE_SECTION_HEADER 【区块表,共占40字节】
{
+00 h BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 节表名称,如“.text”【共占8字节】
+08 h union
{ DWORD PhysicalAddress; // 物理地址
DWORD VirtualSize; // 真实长度,这两个值是一个联合结构,可以使
用其中的任何一个,一般是取后一个
} Misc;
+0C h DWORD VirtualAddress; // 节区的虚拟内存中RVA地址
+10 h DWORD SizeOfRawData; // 节表在文件中对齐后的尺寸
+14 h DWORD PointerToRawData; // 节表在文件中的偏移量
+18 h DWORD PointerToRelocations; // 在OBJ文件中使用,重定位的偏移
+1C h DWORD PointerToLinenumbers; // 行号表的偏移(供调试使用地)
+20 h WORD NumberOfRelocations; // 在OBJ文件中使用,重定位项数目
+22 h WORD NumberOfLinenumbers; // 行号表中行号的数目
+24 h DWORD Characteristics; // 节属性如可读,可写,可执行等
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
⑤:IMAGE_IMPORT_DESCRIPTOR STRUCT 【输入表结构,共20字节】
{
+00 h union
{DWORD Characteristics ; 不知到是神马浮云,不重要
DWORD OriginalFirstThunk //指向IMAGE_THUNK_DATA数组的指针
}ends
+04 h DWORD TimeDateStamp //可执行文件是否与DLL绑定,不绑定为0
+08 h DWORD ForwarderChain //第一个转向的API索引
+0C h DWORD Name //指向DLL的虚拟RVA
+10 h DWORD FirstThunk //实际指向IMAGE_THUNK_DATA数组的指针,结构体一
};IMAGE_IMPORT_DESCRIPTOR ENDS
结构体一:IMAGE_THUNK_DATA STRUC 【共占4字节】
{
union u1
{DWORD ForwarderString ; 指向一个转向者字符串的RVA
DWORD Function ; 被输入的函数的内存地址
DWORD Ordinal ; 被输入的API的序数值
DWORD AddressOfData ; 高位为0则指向IMAGE_IMPORT_BY_NAME 结构体二
}ends
}IMAGE_THUNK_DATA ENDS
结构体二:IMAGE_IMPORT_BY_NAME STRUCT 【共占大小动态分配】
{
+00 h WORD Hint //可选指向函数字段,神马的浮云
+04 h BYTE Name ? //此处内存大小动态分配,定义了导入函数的以0结尾的字符串
};IMAGE_IMPORT_BY_NAME ENDS
PE文件:节表(区块表)PE文件中所有节的属性都被定义在节表中,节表由一系列的IMAGE_SECTION_HEADER结构排列而成,每个结构用来描述一个节,结构的排列顺序和它们描述的节在文件中的排列顺序是一致的。全部有效结构的最后以一个空的IMAGE_SECTION_HEADER结构作为结束,所以节表中总的IMAGE_SECTION_HEADER结构数量等于节的数量加一。节表总是被存放在紧接在PE文件头的地方。
另外,节表中 IMAGE_SECTION_HEADER 结构的总数总是由PE文件头 IMAGE_NT_HEADERS 结构中的 FileHeader.NumberOfSections 字段来指定的。
此结构体共占40个字节 typedef struct _IMAGE_SECTION_HEADER
{
+0h BYTE Name[IMAGE_SIZEOF_SHORT_NAME]; // 节表名称,如“.text”
//IMAGE_SIZEOF_SHORT_NAME=8
union
+8h {
DWORD PhysicalAddress; // 物理地址
DWORD VirtualSize; // 真实长度,这两个值是一个联合结构,可以使用其中的任何一个,一
// 般是取后一个
} Misc;
+ch DWORD VirtualAddress; // 节区的 RVA 地址
+10h DWORD SizeOfRawData; // 在文件中对齐后的尺寸
+14h DWORD PointerToRawData; // 在文件中的偏移量
+18h DWORD PointerToRelocations; // 在OBJ文件中使用,重定位的偏移
+1ch DWORD PointerToLinenumbers; // 行号表的偏移(供调试使用地)
+1eh WORD NumberOfRelocations; // 在OBJ文件中使用,重定位项数目
+20h WORD NumberOfLinenumbers; // 行号表中行号的数目
+24h DWORD Characteristics; // 节属性如可读,可写,可执行等
} IMAGE_SECTION_HEADER, *PIMAGE_SECTION_HEADER;
Name: 区块名。这是一个由8位的ASCII
码名,用来定义区块的名称。多数区块名都习惯性以一个“.”作为开头(例如:.text),这个“.”
实际上是不是必须的。值得我们注意的是,如果区块名超过 8 个字节,则没有最后的终止标志“NULL” 字节。并且前边带有一个“$”
的区块名字会从连接器那里得到特殊的待遇,前边带有“$” 的相同名字的区块在载入时候将会被合并,在合并之后的区块中,他们是按照“$”
后边的字符的字母顺序进行合并的。
另外每个区块的名称都是唯一的,不能有同名的两个区块。但事实上节的名称不代表任何含义,他的存在仅仅是为了正规统一编程的时候方便程序员查看方便而设置的一个标记而已。所以将包含代码的区块命名为“.Data”
或者说将包含数据的区块命名为“.Code” 都是合法的。当我们要从PE
文件中读取需要的区块时候,不能以区块的名称作为定位的标准和依据,正确的方法是按照 IMAGE_OPTIONAL_HEADER32
结构中的数据目录字段结合进行定位。
Virtual Size:该区块表对应的区块的大小,这是区块的数据在没有进行对齐处理前的实际大小。
Virtual Address:该区块装载到内存中的RVA 地址。这个地址是按照内存页来对齐的,因此它的数值总是 SectionAlignment 的值的整数倍。在Microsoft 工具中,第一个快的默认 RVA 总为1000h。在OBJ 中,该字段没有意义地,并被设为0。
SizeOfRawData:该区块在磁盘中所占的大小。在可执行文件中,该字段是已经被FileAlignment 潜规则处理过的长度。
PointerToRawData:该区块在磁盘中的偏移。这个数值是从文件头开始算起的偏移量哦。
PointerToRelocations:这哥们在EXE文件中没有意义,在OBJ 文件中,表示本区块重定位信息的偏移值。(在OBJ 文件中如果不是零,它会指向一个IMAGE_RELOCATION 结构的数组)
PointerToLinenumbers:行号表在文件中的偏移值,文件的调试信息,于我们没用,鸡肋。
NumberOfRelocations:这哥们在EXE文件中也没有意义,在OBJ 文件中,是本区块在重定位表中的重定位数目来着。
NumberOfLinenumbers:该区块在行号表中的行号数目,鸡肋。
Characteristics:该区块的属性。该字段是按位来指出区块的属性(如代码/数据/可读/可写等)的标志。
- IMAGE_SCN_CNT_CODE
- 0x00000020
|
The section contains executable code.
包含代码,常与 0x10000000一起设置。
|
- IMAGE_SCN_CNT_INITIALIZED_DATA
- 0x00000040
|
The section contains initialized data.
该区块包含以初始化的数据。
|
- IMAGE_SCN_CNT_UNINITIALIZED_DATA
- 0x00000080
|
The section contains uninitialized data.
该区块包含未初始化的数据。
|
- IMAGE_SCN_MEM_DISCARDABLE
- 0x02000000
|
The section can be discarded as needed.
该区块可被丢弃,因为当它一旦被装入后,
进程就不在需要它了,典型的如重定位区块。
|
- IMAGE_SCN_MEM_SHARED
- 0x10000000
|
The section can be shared in memory.
该区块为共享区块。
|
- IMAGE_SCN_MEM_EXECUTE
- 0x20000000
|
The section can be executed as code.
该区块可以执行。通常当0x00000020被设置
时候,该标志也被设置。
|
- IMAGE_SCN_MEM_READ
- 0x40000000
|
The section can be read.
该区块可读,可执行文件中的区块总是设置该
标志。
|
- IMAGE_SCN_MEM_WRITE
- 0x80000000
|
The section can be written to.
该区块可写。
|
具体内容可以参考MSDN在线文档:http://msdn.microsoft.com/en-us/library/ms680341(v=vs.85).aspx
区块描述、对齐值以及RVA详解
通常,区块中的数据在逻辑上是关联的。PE
文件一般至少都会有两个区块:一个是代码块,另一个是数据块。每一个区块都需要有一个截然不同的名字,这个名字主要是用来表达区块的用途。例如有一个区块
叫.rdata,表明他是一个只读区块。注意:区块在映像中是按起始地址(RVA)来排列的,而不是按字母表顺序。
另外,使用区块名字只是人们为了认识和编程的方便,而对操作系统来说这些是无关紧要的。微软给这些区块取了个有特色的名字,但这不是必须的。当编程从PE
文件中读取需要的内容时,如输入表、输出表,不能以区块名字作为参考,正确的方法是按照数据目录表中的字段来进行定位。
各种区块的描述:



区块一般是从OBJ 文件开始,被编译器放置的。链接器的工作就是合并左右OBJ 和库中需要的块,使其成为一个最终合适的区块。链接器会遵循一套相当完整的规则,它会判断哪些区块将被合并以及如何被合并。
合并区块:
链接器的一个有趣特征就是能够合并区块。如果两个区块有相似、一致性的属性,那么它们在链接的时候能被合并成一个单一的区块。这取决于是否开启编译器的
/merge 开关。事实上合并区块有一个好处就是可以节省磁盘的内存空间……注意:我们不应该将.rsrc、.reloc、.pdata
合并到++的区块里。
区块的对齐值:
之前我们简单了解过区块是要对齐的,无论是在内存中存放还是在磁盘中存放~但他们一般的对齐值是不同的。
PE 文件头里边的FileAligment 定义了磁盘区块的对齐值。每一个区块从对齐值的倍数的偏移位置开始存放。而区块的实际代码或数据的大小不一定刚好是这么多,所以在多余的地方一般以00h 来填充,这就是区块间的间隙。
例如,在PE文件中,一个典型的对齐值是200h
,这样,每个区块都将从200h 的倍数的文件偏移位置开始,假设第一个区块在400h 处,长度为90h,那么从文件400h 到490h
为这一区块的内容,而由于文件的对齐值是200h,所以为了使这一区块的长度为FileAlignment 的整数倍,490h 到 600h
这一个区间都会被00h 填充,这段空间称为区块间隙,下一个区块的开始地址为600h 。
PE 文件头里边的SectionAligment 定义了内存中区块的对齐值。PE 文件被映射到内存中时,区块总是至少从一个页边界开始。
一般在X86 系列的CPU 中,页是按4KB(1000h)来排列的;在IA-64 上,是按8KB(2000h)来排列的。所以在X86 系统中,PE文件区块的内存对齐值一般等于 1000h,每个区块按1000h 的倍数在内存中存放。
RVA 和文件偏移的转换
在前边我们探讨过RVA 这个词,但对于初次接触PE 文件的朋友来说,显得尤其陌生和无奈。中国人不喜欢老外的缩写,但总要**着接受……不过,在有了前边知识的铺垫之后,现在来谈这个概念大家伙应该能够得心应手了。起码不用显得那么的费解和无奈~
RVA 是相对虚拟地址(Relative Virtual Address)的缩写,顾名思义,它是一个“相对地址”。PE 文件中的各种数据结构中涉及地址的字段大部分都是以 RVA 表示的,有木有??
更为准确的说,RVA
是当PE 文件被装载到内存中后,某个数据位置相对于文件头的偏移量。举个例子,如果 Windows 装载器将一个PE 文件装入到
00400000h 处的内存中,而某个区块中的某个数据被装入 0040**xh 处,那么这个数据的 RVA 就是(0040**xh -
00400000h )= **xh,反过来说,将 RVA 的值加上文件被装载的基地址,就可以找到数据在内存中的实际地址。
DOS 文件头、PE 文件头和区块表的偏移位置与大小均没有变化。而各个区块映射到内存后,其偏移位置就发生了变化。
RVA 使得文件装入内存后的数据定位变得方便,然而却给我们要定位位于磁盘上的静态PE 文件带来了麻烦。举个例子说话:……由于例子在视频中,这里争取时间我就不写啦,大伙看参考视频演示吧。
如何换算 RVA 和文件偏移呢?
当处理PE 文件时候,任何的 RVA 必须经过到文件偏移的换算,才能用来定位并访问文件中的数据,但换算却无法用一个简单的公式来完成,事实上,唯一可用的方法就是最土最笨的方法:
步骤一:循环扫描区块表得出每个区块在内存中的起始
RVA(根据IMAGE_SECTION_HEADER 中的VirtualAddress
字段),并根据区块的大小(根据IMAGE_SECTION_HEADER 中的SizeOfRawData 字段)算出区块的结束
RVA(两者相加即可),最后判断目标 RVA 是否落在该区块内。
步骤二:通过步骤一定位了目标 RVA 处于具体的某个区块中后,那么用目标 RVA 减去该区块的起始 RVA ,这样就能得到目标 RVA 相对于起始地址的偏移量 RVA2.
步骤三:在区块表中获取该区块在文件中所处的偏移地址(根据IMAGE_SECTION_HEADER 中的PointerToRawData 字段), 将这个偏移值加上步骤二得到的 RVA2 值,就得到了真正的文件偏移地址。 输入表(导入表)详解
首先,我们知道PE
文件中的数据被载入内存后根据不同页面属性被划分成很多区块(节),并有区块表(节表)的数据来描述这些区块。这里我们需要注意的问题是:一个区块中的数
据仅仅只是由于属性相同而放在一起,并不一定是同一种用途的内容。例如输入表、输出表等就有可能和只读常量一起被放在同一个区块中,因为他们的属性都是可
读不可写的。
其次,由于不同用途的数据有可能被放入同一个区块中,因此仅仅依靠区块表是无法确定和定位的。那要怎么办?对了,PE
文件头中 IMAGE_OPTIONAL_DEADER32
结构的数据目录表来指出他们的位置,我们可以由数据目录表来定位的数据包括输入表、输出表、资源、重定位表和TLS等15 种数据。
输入函数
在代码分析或编程中经常遇到“输入函数(Import
Functions,也称导入函数)”的概念。这里我们就来解释下,输入函数就是被程序调用但其执行代码又不在程序中的函数,这些函数的代码位于相关的
DLL 文件中,在调用者程序中只保留相关的函数信息(如函数名、DLL 文件名等)就可以。对于磁盘上的PE
文件来说,它无法得知这些输入函数在内存中的地址,只有当PE 文件被装入内存后,Windows 加载器才将相关DLL
装入,并将调用输入函数的指令和函数实际所处的地址联系起来。这就是“动态链接”的概念。动态链接是通过PE
文件中定义的“输入表”来完成的,输入表中保存的正是函数名和其驻留的DLL 名等。
输入表结构
在
PE文件头的 IMAGE_OPTIONAL_HEADER 结构中的 DataDirectory(数据目录表)
的第二个成员就是指向输入表的。而输入表是以一个 IMAGE_IMPORT_DESCRIPTOR(简称IID) 的数组开始。每个被
PE文件链接进来的 DLL文件都分别对应一个 IID数组结构。在这个
IID数组中,并没有指出有多少个项(就是没有明确指明有多少个链接文件),但它最后是以一个全为NULL(0) 的 IID 作为结束的标志。
IMAGE_IMPORT_DESCRIPTOR 结构定义如下:
IMAGE_IMPORT_DESCRIPTOR STRUCT
{
union
Characteristics DWORD ?
OriginalFirstThunk DWORD ?
ends
TimeDateStamp DWORD ?
ForwarderChain DWORD ?
Name DWORD ?
FirstThunk DWORD ?
}IMAGE_IMPORT_DESCRIPTOR ENDS 成员介绍:
OriginalFirstThunk
它指向first thunk,IMAGE_THUNK_DATA,该 thunk 拥有 Hint 和 Function name 的地址。
TimeDateStamp
该字段可以忽略。如果那里有绑定的话它包含时间/数据戳(time/data stamp)。如果它是0,就没有绑定在被导入的DLL中发生。在最近,它被设置为0xFFFFFFFF以表示绑定发生。
ForwarderChain
一般情况下我们也可以忽略该字段。在老版的绑定中,它引用API的第一个forwarder chain(传递器链表)。它可被设置为0xFFFFFFFF以代表没有forwarder。
Name
它表示DLL 名称的相对虚地址(译注:相对一个用null作为结束符的ASCII字符串的一个RVA,该字符串是该导入DLL文件的名称,如:KERNEL32.DLL)。
FirstThunk
它包含由IMAGE_THUNK_DATA定义的
first thunk数组的虚地址,通过loader用函数虚地址初始化thunk。在Orignal First
Thunk缺席下,它指向first thunk:Hints和The Function names的thunks。
这个OriginalFirstThunk 和 FirstThunk明显是亲家,两家伙首先名字就差不多哈。那他们有什么不可告人的秘密呢?来,我们看下面一张图

我们看到:OriginalFirstThunk
和 FirstThunk 他们都是两个类型为IMAGE_THUNK_DATA
的数组,它是一个指针大小的联合(union)类型。每一个IMAGE_THUNK_DATA
结构定义一个导入函数信息(即指向结构为IMAGE_IMPORT_BY_NAME 的家伙,这家伙稍后再议),然后数组最后以一个内容为0 的
IMAGE_THUNK_DATA 结构作为结束标志。
我们得到 IMAGE_THUNK_DATA 结构的定义如下:
IMAGE_THUNK_DATA STRUC
union u1
ForwarderString DWORD ? ; 指向一个转向者字符串的RVA
Function DWORD ? ; 被输入的函数的内存地址
Ordinal DWORD ? ; 被输入的API 的序数值
AddressOfData DWORD ? ; 指向 IMAGE_IMPORT_BY_NAME
ends
IMAGE_THUNK_DATA ENDS
我们可以看出由于是union结构,所以IMAGE_THUNK_DATA
事实上是一个双字大小。该结构在不同时候赋予不同的意义(伟大神奇不得鸟……)。其实union这种数据结构很容易理解:说白了就是当时穷,能省就省,再
说白了,就是几兄弟姐妹轮流穿一条裤子去相亲!理解了吧?哈哈~
那我们怎么来区分何时是何意义呢?
规定如下:
当 IMAGE_THUNK_DATA 值的最高位为 1时,表示函数以序号方式输入,这时候低 31位被看作一个函数序号。
当 IMAGE_THUNK_DATA 值的最高位为 0时,表示函数以字符串类型的函数名方式输入,这时双字的值是一个 RVA,指向一个 IMAGE_IMPORT_BY_NAME 结构。(演示请看小甲鱼解密系列视频讲座)
好,那接着我们讨论下指向的这个 IMAGE_IMPORT_BY_NAME 结构。IMAGE_IMPORT_BY_NAME 结构仅仅只有一个字型数据的大小,存有一个输入函数的相关信息结构。其结构如下:
IMAGE_IMPORT_BY_NAME STRUCT
Hint WORD ?
Name BYTE ?
IMAGE_IMPORT_BY_NAME ENDS
结构中的 Hint 字段也表示函数的序号,不过这个字段是可选的,有些编译器总是将它设置为 0,Name 字段定义了导入函数的名称字符串,这是一个以 0 为结尾的字符串。
整个过程看起来有点绕有点烦,别急,后边我们有演示哈。
输入地址表(IAT)
为什么由两个并行的指针数组同时指向
IMAGE_IMPORT_BY_NAME 结构呢?第一个数组(由 OriginalFirstThunk
所指向)是单独的一项,而且不能被改写,我们前边称为 INT。第二个数组(由 FirstThunk 所指向)事实上是由 PE 装载器重写的。
好了,那么 PE 装载器的核心操作时如何的呢?这里就给大家揭秘啦~
PE
装载器首先搜索 OriginalFirstThunk ,找到之后加载程序迭代搜索数组中的每个指针,找到每个
IMAGE_IMPORT_BY_NAME 结构所指向的输入函数的地址,然后加载器用函数真正入口地址来替代由 FirstThunk
数组中的一个入口,因此我们称为输入地址表(IAT)。所以,当我们的 PE 文件装载内存后准备执行时,刚刚的图就会转化为下图:

此时,输入表中其他部分就不重要了,程序依靠 IAT 提供的函数地址就可正常运行 IMAGE_EXPORT_DIRECTORY STRUCT导出表
当PE 文件被执行的时候,Windows 加载器将文件装入内存并将导入表(Export Table) 登记的动态链接库(一般是DLL 格式)文件一并装入地址空间,再根据DLL 文件中的函数导出信息对被执行文件的IAT 进行修正。
导出表就是记载着动态链接库的一些导出信息。通过导出表,DLL 文件可以向系统提供导出函数的名称、序号和入口地址等信息,比便Windows 加载器通过这些信息来完成动态连接的整个过程。
注意:扩展名为.exe 的PE 文件中一般不存在导出表,而大部分的.dll 文件中都包含导出表。但注意,这并不是绝对的。例如纯粹用作资源的.dll 文件就不需要导出函数啦,另外有些特殊功能的.exe 文件也会存在导出函数。
导出表结构
导出表(Export
Table)中的主要成分是一个表格,内含函数名称、输出序数等。序数是指定DLL 中某个函数的16位数字,在所指向的DLL
文件中是独一无二的。在此我们不提倡仅仅通过序数来索引函数的方法,这样会给DLL 文件的维护带来问题。例如当DLL
文件一旦升级或修改就可能导致调用改DLL 的程序无法加载到需要的函数。
数据目录表的第一个成员指向导出表,是一个IMAGE_EXPORT_DIRECTORY(以后简称IED)结构,IED 结构的定义如下:
IMAGE_EXPORT_DIRECTORY STRUCT【导出表,共40字节】
{
+00 h DWORD Characteristics ; 未使用,总是定义为0
+04 h DWORD TimeDateStamp ; 文件生成时间
+08 h WORD MajorVersion ; 未使用,总是定义为0
+0A h WORD MinorVersion ; 未使用,总是定义为0
+0C h DWORD Name ; 模块的真实名称
+10 h DWORD Base ; 基数,加上序数就是函数地址数组的索引值
+14 h DWORD NumberOfFunctions ; 导出函数的总数
+18 h DWORD NumberOfNames ; 以名称方式导出的函数的总数
+1C h DWORD AddressOfFunctions ; 指向输出函数地址的RVA
+20 h DWORD AddressOfNames ; 指向输出函数名字的RVA
+24 h DWORD AddressOfNameOrdinals ; 指向输出函数序号的RVA
};IMAGE_EXPORT_DIRECTORY ENDS
这个结构中的一些字段并没有被使用,有意义的字段说明如下。
Name:
一个RVA 值,指向一个定义了模块名称的字符串。如即使Kernel32.dll 文件被改名为"Ker.dll",仍然可以从这个字符串中的值得知其在编译时的文件名是"Kernel32.dll"。
NumberOfFunctions:
文件中包含的导出函数的总数。
NumberOfNames:
被定义函数名称的导出函数的总数,显然只有这个数量的函数既可以用函数名方式导出。也可以用序号方式导出,剩下
的NumberOfFunctions 减去NumberOfNames 数量的函数只能用序号方式导出。该字段的值只会小于或者等于
NumberOfFunctions 字段的值,如果这个值是0,表示所有的函数都是以序号方式导出的。
AddressOfFunctions:
一个RVA 值,指向包含全部导出函数入口地址的双字数组。数组中的每一项是一个RVA 值,数组的项数等于NumberOfFunctions 字段的值。
Base:导出函数序号的起始值,将AddressOfFunctions
字段指向的入口地址表的索引号加上这个起始值就是对应函数的导出 序号。假如Base
字段的值为x,那么入口地址表指定的第1个导出函数的序号就是x;第2个导出函数的序号就是x+1。总之,一个导出函数的导出序号等 于Base
字段的值加上其在入口地址表中的位置索引值。
AddressOfNames 和 AddressOfNameOrdinals:
均为RVA
值。前者指向函数名字符串地址表。这个地址表是一个双字数组,数组中的每一项指向一个函数名称字符串的RVA。数组的项数等于NumberOfNames
字段的值,所有有名称的导出函数的名称字符串都定义在这个表中;后者指向另一个word
类型的数组(注意不是双字数组)。数组项目与文件名地址表中的项目一一对应,项目值代表函数入口地址表的索引,这样函 数名称与函数入口地址关联起来。
整个流程跟其他PE 结构图:
1. 从序号查找函数入口地址
大家来模拟一下Windows 装载器查找导出函数入口地址的整个过程。如果已知函数的导出序号,如何得到函数的入口地址呢 ?
Windows 装载器的工作步骤如下:
定位到PE 文件头
从PE 文件头中的 IMAGE_OPTIONAL_HEADER32 结构中取出数据目录表,并从第一个数据目录中得到导出表的RVA
从导出表的 Base 字段得到起始序号
将需要查找的导出序号减去起始序号,得到函数在入口地址表中的索引
检测索引值是否大于导出表的 NumberOfFunctions 字段的值,如果大于后者的话,说明输入的序号是无效的
用这个索引值在 AddressOfFunctions 字段指向的导出函数入口地址表中取出相应的项目,这就是函数入口地址的RVA 值,当函数被装入内存的时候,这个RVA 值加上模块实际装入的基地址,就得到了函数真正的入口地址
2. 从函数名称查找入口地址
如果已知函数的名称,如何得到函数的入口地址呢?与使用序号来获取入口地址相比,这个过程要相对复杂一点!
Windows 装载器的工作步骤如下:
最初的步骤是一样的,那就是首先得到导出表的地址
从导出表的 NumberOfNames 字段得到已命名函数的总数,并以这个数字作为循环的次数来构造一个循环
从 AddressOfNames 字段指向得到的函数名称地址表的第一项开始,在循环中将每一项定义的函数名与要查找的函数名相比较,如果没有任何一个函数名是符合的,表示文件中没有指定名称的函数
如果某一项定义的函数名与要查找的函数名符合,那么记下这个函数名在字符串地址表中的索引值,然后在 AddressOfNamesOrdinals 指向的数组中以同样的索引值取出数组项的值,我们这里假设这个值是x
最后,以 x 值作为索引值,在 AddressOfFunctions 字段指向的函数入口地址表中获取的 RVA 就是函数的入口地址
IMAGE_BASE_RELOCATION STRUC基址重定
什么是基址重定位?
答:重定位就是你本来这个程序理论上要占据这个地址,但是由于某种原因,这个地址现在不能让你霸占,你必须转移到别的地址,这就需要基址重定位
但凡涉及到直接寻址的指令都需要进行重定位处理!
IMAGE_BASE_RELOCATION STRUC 【基址重定位位于数据目录表的第六项,共8+N字节】
{
+00 h DWORD VirtualAddress ;重定位数据开始的RVA 地址
+04 h DWORD SizeOfBlock ;重定位块得长度,标识重定向字段个数
+08 h WORD TypeOffset ;重定项位数组相对虚拟RVA,个数动态分配
};
IMAGE_BASE_RELOCATION ENDS
1.VirtualAddress 是 Base Relocation Table 的位置它是一个 RVA 值;
2.SizeOfBlock 是 Base Relocation Table 的大小;
3.TypeOffset 是一个数组,数组每项大小为两个字节(16位),它由高 4位和低 12位组成,高 4位代表重定位类型,低 12位是重定位地址,它与 VirtualAddress 相加即是指向PE 映像中需要修改的那个代码的地址。
TypeOffset高位字节的代码定义:
IMAGE_REL_BASED_ABSOLUTE (0) 使块按照32位对齐,位置为0。
IMAGE_REL_BASED_HIGH (1) 高16位必须应用于偏移量所指高字16位。
IMAGE_REL_BASED_LOW (2) 低16位必须应用于偏移量所指低字16位。
IMAGE_REL_BASED_HIGHLOW (3) 全部32位应用于所有32位。
IMAGE_REL_BASED_HIGHADJ (4) 需要32位,高16位位于偏移量,低16位位于下一个偏移量数组元素,组合为一个带符号数,加上32位的一个数,然后加上8000然后把高16位保存在偏移量的16位域内。
IMAGE_REL_BASED_MIPS_JMPADDR (5) Unknown
IMAGE_REL_BASED_SECTION (6) Unknown
IMAGE_REL_BASED_REL32 (7) Unknown
资源结构体
Windows
将程序的各种界面定义为资源,包括加速键(Accelerator)、位图(Bitmap)、光标(Cursor)、对话框(Dialog
Box)、图标(Icon)、菜单(Menu)、串表(String Table)、工具栏(Toolbar)和版本信息(Version
Information)等。
资源有很多种类型,每种类型的资源中可能存在多个资源项,这些资源项用不同的ID 或者名称来区分。但是要将这么多种类型的不同ID 的资源有序地组织起来是一件非常痛苦的事情,因此,我们采取类似于磁盘目录结构的方式保存。
PE 文件中的资源是按照 资源类型 -> 资源ID -> 资源代码页 的3层树型目录结构来组织资源的,通过层层索引才能够进入相应的子目录找到正确的资源。
资源目录结构:
数据目录表中的
IMAGE_DIRECTORY_ENTRY_RESOURCE 条目(第三项)包含资源的 RVA 和大小。资源目录结构中的每一个节点都是由
IMAGE_RESOURCE_DIRECTORY 结构和紧跟其后的数个IMAGE_RESOURCE_DIRECTORY_ENTRY 结构组成的。
我们再来看这张图:
IMAGE_RESOURCE_DIRECTORY STRUCT 【资源表位于数据目录表的第三项,共动态分配字节,其中结构体中的成员指出的RVA偏移量都是对于此结构体的地址作为基地址】
{
+00 h DWORD Characteristics ; 理论上为资源的属性,不过事实上总是0
+04 h DWORD TimeDateStamp ; 资源的产生时刻
+08 h WORD MajorVersion ; 理论上为资源的版本,不过事实上总是0
+0A h WORD MinorVersion
+0C h WORD NumberOfNamedEntries ; 以名称(字符串)命名的入口数量
+0E h WORD NumberOfIdEntries ; 以ID(整型数字)命名的入口数量
};IMAGE_RESOURCE_DIRECTORY ENDS
后面紧接着一个结构体,个数由上个结构指出:
IMAGE_RESOURCE_DIRECTORY_ENTRY STRUCT
{
+10 h DWORD Name ; 目录项的名称字符串指针或ID,高位为1时指向子结构体一
+14 h DWORD OffsetToData ; 目录项指针,高位为1时指向子结构体二
};IMAGE_RESOURCE_DIRECTORY_ENTRY ENDS
Name
字段完全是个百变精灵,改字段定义的是目录项的名称或ID。
当结构用于第一层目录时,定义的是资源类型;
当结构定义于第二层目录时,定义的是资源的名称;
当结构用于第三层目录时,定义的是代码页编号。
注意:
当最高位为 0 的时候,表示字段的值作为 ID 使用;
而最高位为 1 的时候,字段的低位作为指针使用(资源名称字符串是使用 UNICODE编码),但是这个指针不是直接指向字符串,而是指向一个IMAGE_RESOURCE_DIR_STRING_U 结构的。
子结构体一:
IMAGE_RESOURCE_DIR_STRING_U STRUCT
{
+00 h DWORD Length ; 字符串的长度
+04 h DWORD NameString ; UNICODE字符串,由于字符串是不定长的。由Length 制定长度
};IMAGE_RESOURCE_DIR_STRING_U ENDS
OffsetOfData
字段是一个指针,
当最高位为 1 时,低位数据指向下一层目录块的其实地址;
当最高位为 0 时,指针指向 IMAGE_RESOURCE_DATA_ENTRY 结构。
注意:将 Name 和 OffsetToData 用做指针时需要注意,该指针是从资源区块开始的地方算起的偏移量(即根目录的起始位置的偏移量),不是我们习惯的 RVA 哦。
最后,在上图中我们看到,在第一层的时候,IMAGE_RESOURCE_DIRECTORY_ENTRY 的Name 字段作为资源类型使用。
具体类型匹配见下表:

经过三层 IAMGE_RESOURCE_DIRECTORY_ENTRY (一般是3层,偶尔少一些。第一层资源类型,第二层资源名,第三层是资源的 Language),第三层目录结构中的 OffsetOfData 指向 IMAGE_RESOURCE_DATA_ENTRY 结构。该结构描述了资源数据的位置和大小,定义如下:
子结构体二:
IMAGE_RESOURCE_DATA_ENTRY STRUCT
{
+00 h DWORD OffsetToData ; 资源数据的RVA
+04 h DWORD Size ; 资源数据的长度
+08 h DWORD CodePage ; 代码页, 一般为0
+0C h DWORD Reserved ; 保留字段
};IMAGE_RESOURCE_DATA_ENTRY ENDS 此处的 IMAGE_RESOURCE_DATA_ENTRY 结构就是真正的资源数据了。结构中的OffsetOfData 指向资源数据的指针,其为 RVA 值。
/************************************************************************/
/*
功能:判断是否是PE文件。
参数:指向存放文件数据内存首地址
返回:TRUE ;是PE文件
FALSE:不是PE文件
*/
/************************************************************************/
BOOL IsPEFile(LPVOID lpFileBuf)
{
//获取DOS头并判断"MZ"标志
PIMAGE_DOS_HEADER pDos = (PIMAGE_DOS_HEADER)lpFileBuf;
//e_magic exe标志 "MZ"
if (IMAGE_DOS_SIGNATURE != pDos->e_magic)
return FALSE;
//获取PE头,并判断"PE\0\0"标志
//e_lfanew PE头相对于文件的偏移地址
size_t stPEHeadAddr = (size_t)lpFileBuf + pDos->e_lfanew;
PIMAGE_NT_HEADERS32 pNT = (PIMAGE_NT_HEADERS32)stPEHeadAddr;
if (IMAGE_NT_SIGNATURE != pNT->Signature)
{
return FALSE;
}
return TRUE;
}
int _tmain(int argc, _TCHAR* argv[])
{
//文件句柄
HANDLE hFile = INVALID_HANDLE_VALUE;
//文件路径
LPCTSTR strInPath = _T("G:\\15pb培训课后作业\\01 VMView\\Debug\\VMView.exe");
DWORD dwSize = 0;
PVOID lpFillBuf = NULL;
STARTUPINFO si = { 0 };
GetStartupInfo(&si);
PROCESS_INFORMATION pi = { 0 };
if (!CreateProcess( /* 创建调试线程 */
strInPath, //可执行模块路径
NULL, //命令行
NULL, //安全描述符
NULL, //线程属性是否可继承
FALSE, //否从调用进程处继承了句柄
DEBUG_ONLY_THIS_PROCESS | CREATE_NEW_CONSOLE, //以“只”调试的方式启动
NULL, //新进程的环境块
NULL, //新进程的当前工作路径(当前目录)
&si, //指定进程的主窗口特性
&pi)) //接收新进程的识别信息
{
printf("CreateProcess Failed!\n");
}
//获取文件句柄
if (INVALID_HANDLE_VALUE == (hFile = CreateFile(strInPath, //文件路径
GENERIC_READ, //访问权限
FILE_SHARE_READ, //共享模式
NULL, //安全描述符
OPEN_EXISTING, //创建标志
FILE_ATTRIBUTE_NORMAL, //文件标志和属性
NULL))) //临时文件句柄
{
return 0;
}
//获取文件大小
if (INVALID_FILE_SIZE == (dwSize = GetFileSize(hFile, NULL)))
{
CloseHandle(hFile);
return 0;
}
//开辟一块内存用于存放文件数据
if (NULL == (lpFillBuf = VirtualAlloc(NULL, dwSize, MEM_COMMIT, PAGE_EXECUTE_READWRITE)))
{
CloseHandle(hFile);
return 0;
}
//把文件数据读取到内存中
DWORD dwRet;
if (!ReadFile(hFile, lpFillBuf, dwSize, &dwRet, NULL))
{
CloseHandle(hFile);
VirtualFree(lpFillBuf, 0, MEM_RELEASE);
return 0;
}
if (IsPEFile(lpFillBuf))
{
MessageBox(NULL, _T("该文件是PE文件"), _T("PE文件格式判断"), MB_OK);
}
else
{
MessageBox(NULL, _T("该文件不是PE文件"), _T("PE文件格式判断"), MB_OK);
}
VirtualFree(lpFillBuf, 0, MEM_RELEASE);
CloseHandle(hFile);
_tsystem(_T("pause"));
return 0;
}
|