|
主要参考《数据挖掘:R语言实战》(黄文,王正林编著)
在收集数据过程中,绝大多数情况下,并不采取普查的方式获取总体中所有样本的数据信息,而是以各类抽样方法抽取其中若干代表性样本来进行数据获取和分析。在获得待分析数据集后,需要再次通过抽样技术选取出训练集和测试集,以便比较选择出最优的挖掘算法。
这里主要介绍简单随机抽样、分层抽样、整群抽样三种基本抽样方法。
用到的软件包及函数
|
软件包
|
函数
|
函数意义
|
|
base(无需加载,默认含有)
|
sample()
|
简单随机抽样
|
|
Sampling(需下载)
|
stratr()
|
分层抽样
|
|
cluster()
|
整群抽样
|
简单随机抽样
sample(x, size, replace = FALSE, prob =NULL)
x: 带抽取对象
size: 想要抽取的样本数量
replace: 是否为有放回,默认为FALSE,即无放回
prob: 设置个抽取样本的抽样概率,默认为无取值,即等概率抽样
例子,以MASS包中的Insurance数据集为例:


实现无放回抽样时,只需不对replace参数进行设置即可,此时size的取值不可以超过x的长度。
分层抽样
strata(data, stratanames=NULL, size, method=c("srswor","srswr","poisson","systematic"),pik,description=FALSE)
data: 带抽样数据
stratanames: 进行分层所依据的变量名称
size: 各层中要抽出的观测样本数
method: 选择4中抽样方法,分别为无放回、有放回、泊松、系统抽样,默认为srswor
pik: 设置各层中样本的抽样概率
description: 选择是否输出含有各层基本信息的结果

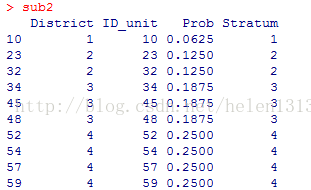
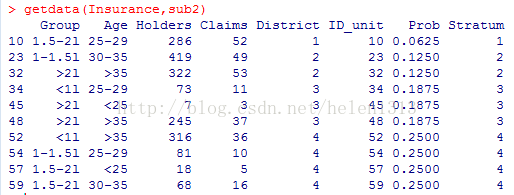
令description = T, 会给出共有多少层,每层中带抽样本总数及实际抽取样本数。

整群抽样
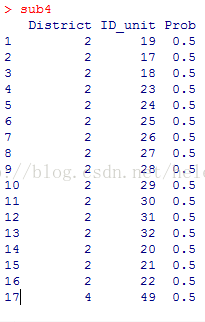
cluster(data, clustername, size, method=c("srswor","srswr","poisson","systematic"),
pik,description=FALSE)
clustername: 用来划分群的变量名称
size:需要抽取的群数

抽中了District = 2,4的两个整群(下图只显示了一部分)
训练集与测试集
x为输入变量,y为输出变量。利用训练集中的x,y建立模型。
将测试集中的x带入模型,来预测测试集目标输出变量y的值,设为y’,将训练集的x带入模型,来预测训练集目标输出变量y的值,设为y’’。那么y’’与y的误差评价了模型的拟合程度,即自己对自己的契合程度;而y’与y的误差则评价了模型的推广程度,即与别人的契合程度。当我们说一个模型相对较好时,往往指该模型的拟合程度和推广程度综合最优。
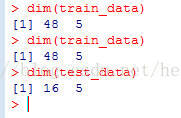
一般控制训练集与测试集之比为3:1:

|
















