|
最近任务重,时间紧,跳票了两个月,真是抱歉。
近期参加了kesci平台上的云脑机器学习训练营,接触到了FFM模型,因此这篇文章,将主要讲述FFM模型在CTR预估中的应用。
看这篇文章之前,如果对FFM模型完全没了解的,建议先看一下FFM的原理介绍:深入FFM原理与实践
FFM(Field-aware Factorization Machine)模型是FM(Factorization Machine)的升级版模型,美团点评技术团队在站内CTR/CVR的预估上使用了该模型,取得了不错的效果。
数据集是一个外国电商网站的用户浏览记录,大家可以在kesci平台上下载,也可以注册kesci账号直接在平台上运行:KASANDR Data Set
from sklearn import preprocessing from sklearn.metrics import roc_auc_score from sklearn import preprocessing import matplotlib.pyplot as plt warnings.filterwarnings('ignore')
画图分析时间特征:
data = pd.read_csv('../input/kasandr/de_cb_camp01/sample_train.csv',sep='\t',index_col='Unnamed: 0') pltdata['date'] = pltdata['utcdate'].apply(lambda x: x.split(' ')[0]) pltdata['hour'] = pltdata['utcdate'].apply(lambda x: x.split(' ')[1].split(':')[0]) plt.figure(figsize = [12,6]) pltdata.groupby('date')['rating'].mean().plot() plt.figure(figsize = [12,6]) pltdata.groupby('hour')['rating'].mean().plot()
结果显示:
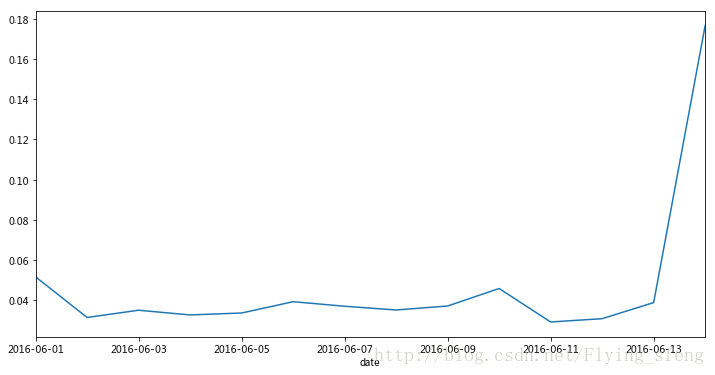

可以看到2016-06-14号的数据明显异常,所以在应用模型时直接弃用了这一天的数据;另外时间段上可以看到工作时间和非工作时间的浏览数是明显不同的。
添加时间特征:
##添加时间特征,即行为发生在每天的哪个时间段,以及根据是否工作时间创建特征(划分阈值由上图2得到) data['hour'] = data['utcdate'].apply(lambda x: x.split(' ')[1].split(':')[0]).astype(int) data['off_work'] = data['hour'].apply(lambda x: 1 if x >= 17 or x <= 1 else 0)
接下来,添加用户及商品相关的特征:
##这部分添加的特征有用户历史浏览数,用户历史浏览的商品数,用户历史浏览的种类数,offerid历史被浏览次数,offerid历史被点击次数 ##文中出现%i变量的原因是:我原来是想对时间滑窗构建特征,比如在前1,3,5,7天内用户即商品的相关统计特征,但由于平台资源限制,这里只做了前7天的相关特征; print ('start adding features...') def add_feat(data,date1,date2,date3,date4,i): train_data = data[(data['utcdate'] >= date1) & (data['utcdate'] <= date2)] train_label = data[(data['utcdate'] >= date3) & (data['utcdate'] <= date4)] label_uid = train_label['userid'].unique() train_userid = train_data[train_data['userid'].isin(label_uid)] browse = train_userid.groupby(['userid'])['offerid'].count().reset_index() ##用户历史浏览数 browse.columns = ['userid','browse%d'%i] train_label = train_label.merge(browse,on=['userid'],how='left') subdata1 = train_userid.drop_duplicates(['userid','merchant']) ##用户历史浏览的商品数 merchant = subdata1.groupby(['userid'])['merchant'].count().reset_index() merchant.columns = ['userid','merchant%d'%i] train_label = train_label.merge(merchant,on=['userid'],how='left') subdata2 = train_userid.drop_duplicates(['userid','category']) ##用户历史浏览的种类数 category = subdata2.groupby(['userid'])['category'].count().reset_index() category.columns = ['userid','category%d'%i] train_label = train_label.merge(category,on=['userid'],how='left') label_offerid = train_label['offerid'].unique() train_offer = train_data[train_data['offerid'].isin(label_offerid)] offerid_num = train_offer.groupby(['offerid'])['userid'].count().reset_index() ##offerid历史被浏览次数 offerid_num.columns = ['offerid','offerid_num%d'%i] train_label = train_label.merge(offerid_num,on=['offerid'],how='left') offer_rating = train_offer.groupby(['offerid'])['rating'].sum().reset_index() ##offerid历史被点击次数 offer_rating.columns = ['offerid','offer_rating%d'%i] train_label = train_label.merge(offer_rating,on=['offerid'],how='left') train_label[['browse%d'%i,'merchant%d'%i,'category%d'%i,'offerid_num%d'%i,'offer_rating%d'%i]] = train_label[['browse%d'%i,'merchant%d'%i,'category%d'%i,'offerid_num%d'%i,'offer_rating%d'%i]].fillna(0) train1 = add_feat(data,'2016-06-01','2016-06-07','2016-06-08','2016-06-09',i=0) train2 = add_feat(data,'2016-06-02','2016-06-08','2016-06-09','2016-06-10',i=0) train3 = add_feat(data,'2016-06-03','2016-06-09','2016-06-10','2016-06-11',i=0) train4 = add_feat(data,'2016-06-04','2016-06-10','2016-06-11','2016-06-12',i=0) test = add_feat(data,'2016-06-05','2016-06-11','2016-06-12','2016-06-13',i=0) train = pd.concat([train1,train2,train3,train4],axis=0) len_train = train.shape[0] all_data = pd.concat([train,test],axis=0) print ('finish adding features...')
特征工程做完之后,就是对数据格式的转换(转换成FFM模型需要的格式:“field_id:feat_id:value”),以及使用模型进行训练了:
###将数据格式转换为FFM模型需要的格式,分别对类别型和数值型数据做处理,数值型数据必须做归一化处理,而且处理时训练集和测试集必须在同个 ###变换空间内,我一开始是对训练集和测试集分别归一化后,导致结果非常差;修正后效果提升很多。 field_dict = dict(zip(df.columns,range(len(df.columns)))) if col_type.kind == 'O': ##category数据 col_value = df[col].unique() feat_dict = dict(zip(col_value,range(idx,idx+len(col_value)))) se = df[col].apply(lambda x: (field_dict[col],feat_dict[x],1)) ffm = pd.concat([ffm,se],axis=1) elif col_type.kind == 'i': ##数值型数据 min_max_scaler = preprocessing.MinMaxScaler() ##归一化处理 df[col] = min_max_scaler.fit_transform(df[col]) si = df[col].apply(lambda x: (field_dict[col],field_dict[col],x)) ffm = pd.concat([ffm,si],axis=1) print ('starting FFM...') train_y = train['rating'].values test_y = test['rating'].values all_example = all_data[all_data.columns.difference(['countrycode','utcdate','rating'])] #if col in ['userid','offerid','category','merchant','date','hour','off_work']: if col in ['userid','offerid','category','merchant']: df[col] = df[col].map(str) df[col] = df[col].map(int) all_example = data_str_int(all_example) all_X = pd_to_ffm(all_example) train_X = all_X[:len_train] test_X = all_X[len_train:] ffm_train_data = ffm.FFMData(train_X.values, train_y) ffm_test_data = ffm.FFMData(test_X.values, test_y) # train the model for 20 iterations model = ffm.FFM(eta=0.1, lam=0.0001, k=4) model.init_model(ffm_train_data) print('iteration %d, ' % i, end='') model.iteration(ffm_train_data) train_y_pred = model.predict(ffm_train_data) train_auc = roc_auc_score(train_y, train_y_pred) test_y_pred = model.predict(ffm_test_data) test_auc = roc_auc_score(test_y, test_y_pred) print('train auc %.4f' % train_auc,'test auc %.4f' % test_auc)
模型训练及预测结果:
iteration 0, train auc 0.9363 test auc 0.7920 iteration 1, train auc 0.9761 test auc 0.7962 iteration 2, train auc 0.9901 test auc 0.7977 iteration 3, train auc 0.9961 test auc 0.7980 iteration 4, train auc 0.9984 test auc 0.7994 iteration 5, train auc 0.9993 test auc 0.8005 iteration 6, train auc 0.9996 test auc 0.8011 iteration 7, train auc 0.9998 test auc 0.8012 iteration 8, train auc 0.9999 test auc 0.8014 iteration 9, train auc 0.9999 test auc 0.8016 iteration 10, train auc 0.9999 test auc 0.8016 iteration 11, train auc 1.0000 test auc 0.8016 iteration 12, train auc 1.0000 test auc 0.8015 iteration 13, train auc 1.0000 test auc 0.8012 iteration 14, train auc 1.0000 test auc 0.8012 iteration 15, train auc 1.0000 test auc 0.8012 iteration 16, train auc 1.0000 test auc 0.8011 iteration 17, train auc 1.0000 test auc 0.8009 iteration 18, train auc 1.0000 test auc 0.8007 iteration 19, train auc 1.0000 test auc 0.8005
可以看到,迭代10次左右就开始收敛了。
划重点:数值型特征必须先进行归一化,且必须保证训练集和测试集在同个变换空间内。
本文只是介绍对FFM模型的简单应用,在特征工程上没有特别的花费功夫,适合初学者了解这个模型的使用。
最后,安利一个同学的方案,做的很详细:云脑-电商推荐系统(特征工程部分)
参考:
深入FFM原理与实践
点击率预估算法:FM与FFM
|















