前言几年前,我在刚刚进入大数据领域的时候,很快就了解到Hive所提供的一种另类的SQL。最初使用Hive的命令行提交任务,后来便用上了HiveServer和HiveServer2。半年前第一次注意到Spark的Thrift服务,当时心中就笃定它肯定与HiveServer2有着某种联系,直到在工作中真正使用它。 在使用HiveThriftServer2的过程中,通过故障排查、源码分析和功能优化,HiveThriftServer2的实现及其原理就浮上水面。等我了解了HiveThriftServer2,情不自禁的就会和Tomcat进行一番比较,尤其是在组件的生命周期管理方面。有兴趣的同学可以先阅读下我之前写得《Tomcat7.0源码分析——生命周期管理》一文。Tomcat将内部组件都抽象为容器,而HiveThriftServer2的内部组件都是服务。HiveThriftServer2对服务的抽象不是本来固有的,而是继承自HiveServer2的。根据HiveServer2的设计,所有的服务都需要实现Service接口。 本文将从HiveThriftServer2的Service接口设计、生命周期管理、启动过程分析三个角度深入分析。 一切都是服务早年间火热的SOA技术,有一个关键的修饰语——“一切都是服务”,今天拿来形容HiveThriftServer2及HiveServer2中的组件抽象却恰如其分。HiveServer2定义了Service接口,其中包含的接口方法见代码清单1。 代码清单1 Service的定义
有了对这些属性的了解,AbstractService实现的方法如下: 服务初始化 AbstractService实现的初始化方法见代码清单2. 代码清单2 代码清单3 服务启动 AbstractService实现的启动方法见代码清单4. 代码清单4 服务停止 AbstractService实现的启动方法见代码清单5. 代码清单5 监听器的注册与注销AbstractService实现的监听器注册和注销方法见代码清单6.代码清单6 获取服务信息AbstractService实现的获取服务信息的方法见代码清单7.代码清单7 有了Service的基础定义和AbstractService的基础实现,HiveServer2中的所有服务就有了依托。像OperationManager和ThriftCliService就直接继承了AbstractService。在整个设计中,HiveServer2还提供了一个对AbstractService的行为进行了重写的复合组件(CompositeService)用于表示由多种服务组件组合构成的服务组件。HiveServer2中的所有复合组件,比如CLIService、HiveServer2、SessionManager等都继承自CompositeService。HiveThriftServer2通过反射加继承的方式间接的使用了AbstractService和CompositeService。在介绍复合组件之前,我们先展示整个Service的继承体系,如图1所示。 图1 Service的继承体系 复合服务从图1可以看出CompositeService直接继承了AbstractService。CompositeService内部定义了一个用于管理所有子Service的列表: CompositeService重写了AbstractService实现的服务初始化、服务启动、服务停止等方法。 复合服务的初始化CompositeService重写的初始化方法见代码清单8. 代码清单8 复合服务的启动CompositeService重写的启动方法见代码清单9. 代码清单9 复合服务的停止CompositeService重写的停止方法见代码清单10.代码清单10 图1中所示的CLIService、HiveServer2、SessionManager由于继承了CompositeService,所以他们都是复合组件。 HiveThriftServer2与HiveServer2的区别 从图1看到HiveThriftServer2、SparkSQLSessionManager及SparkSQLCLIService在分别继承了HiveServer2、SessionManager及CLIService的同时,又分别实现了ReflectedCompositeService。这种实现貌似很奇怪,但是细细想来其实非常自然。HiveThriftServer2从设计之初就是要重用HiveServer2中的各种功能,这可以大大简化开发的工作量,并且可以直接将HiveServer2已经实现的各种特性继承过来。那么为什么又要实现ReflectedCompositeService呢?在回答这个问题之前,我们先来看看HiveThriftServer2与HiveServer2内部Service的区别,如图2所示。 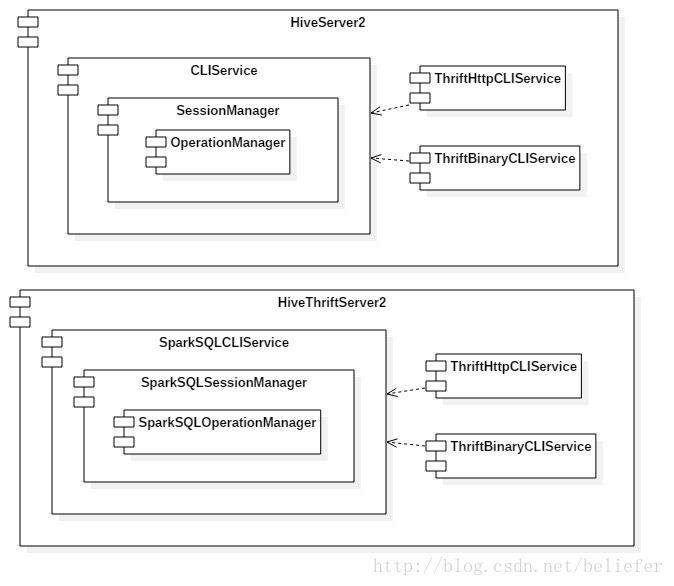 图2 HiveServer2与HiveThriftServer2的对比 从图2看到,HiveServer2的子Service包括CLIService、ThriftHttpCLIService及ThriftBinaryCLIService。而HiveThriftServer2的子Service包括SparkSQLCLIService、ThriftHttpCLIService及ThriftBinaryCLIService。CLIService和SparkSQLCLIService内部也有不同的子Service。由于HiveThriftServer2内部需要使用Spark的一些API,所以HiveThriftServer2不可能单纯的继承HiveServer2。另一方面,由于HiveThriftServer2继承了HiveServer2,所以默认情况下HiveThriftServer2内部的子Service即为HiveServer2内部的子服务,为了给HiveThriftServer2的子Service做一些定制化的扩展,只能通过反射的方式替换HiveServer2内部的子Service。ReflectedCompositeService提供了反射初始化HiveThriftServer2的子Service的实现,见代码清单11. 代码清单11 初始化、启动、停止 无论是HiveThriftServer2还是HiveServer2,除了初始化过程,它们的启动过程、停止过程都是类似的。本节将先分别展示HiveServer2和HiveThriftServer2的初始化过程,然后介绍它们共同的启动过程,至于停止过程和启动过程十分相似,就不过多介绍了。 HiveServer2的初始化过程,如图3所示。 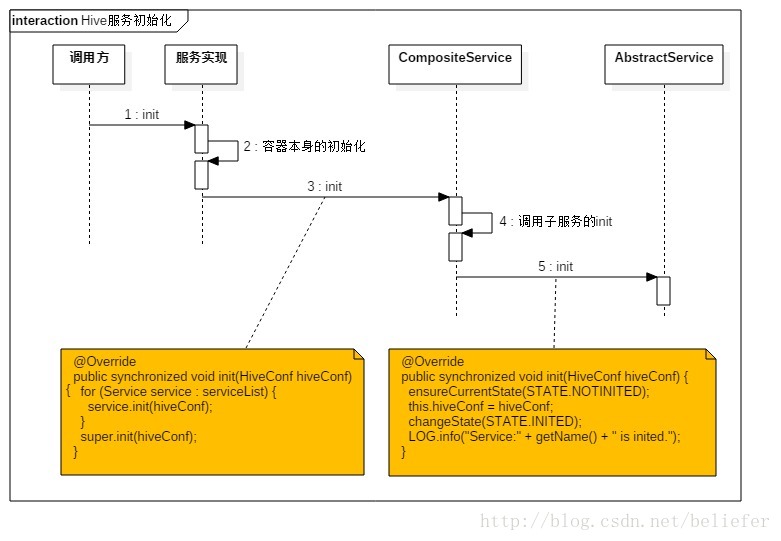 图3 HiveServer2的初始化过程 HiveThriftServer2的初始化过程,如图4所示。 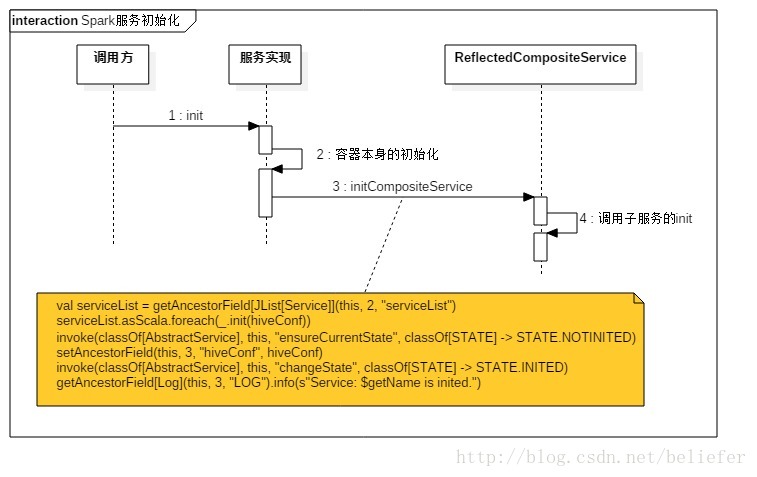 图4 HiveThriftServer2的初始化过程 Service的启动过程,如图5所示。 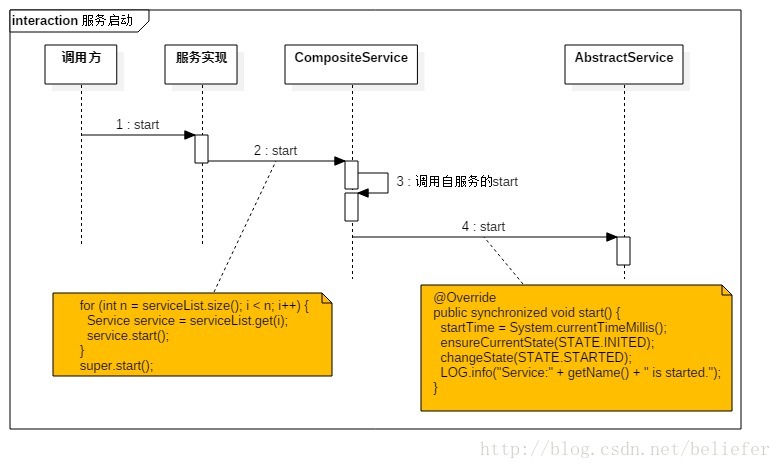 图5 Service的启动过程 由于Service的停止过程与启动过程相类似,因此不再赘述。 最后再附上本文的姊妹篇——《Spark1.6.0功能扩展——为HiveThriftServer2增加HA》  纸质版售卖链接如下: 电子版售卖链接如下: |
|
|















