|
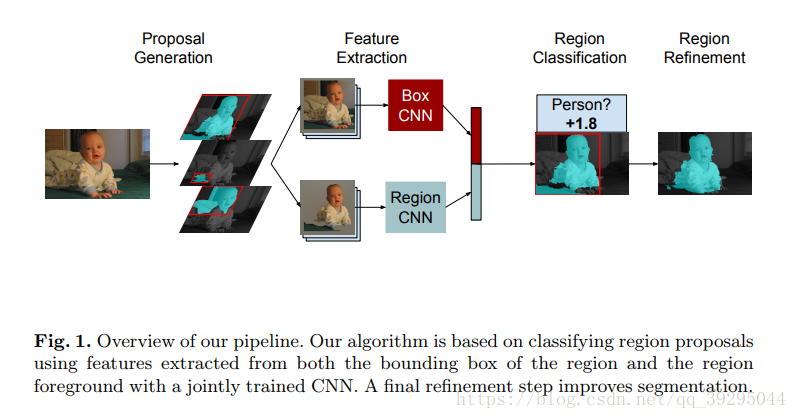
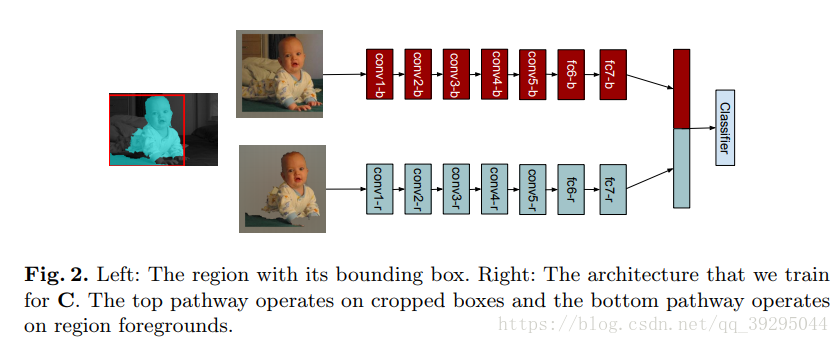
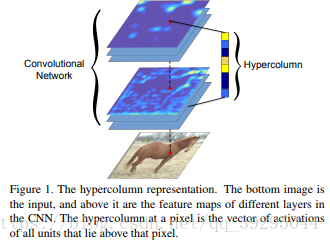
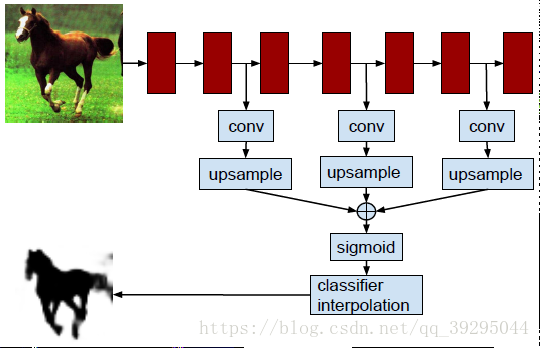
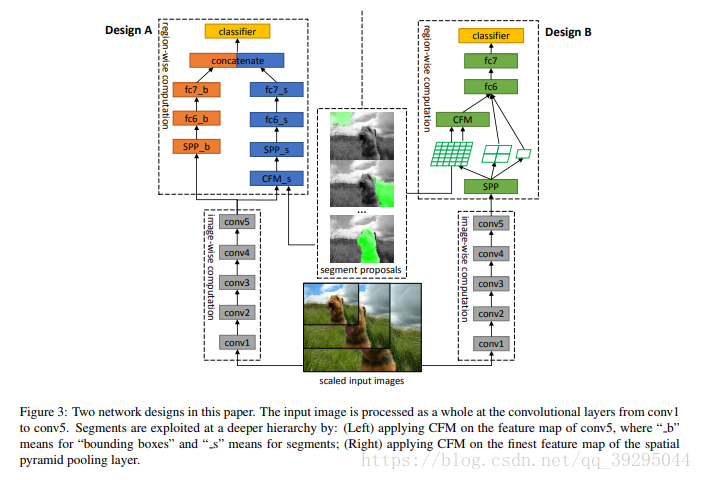
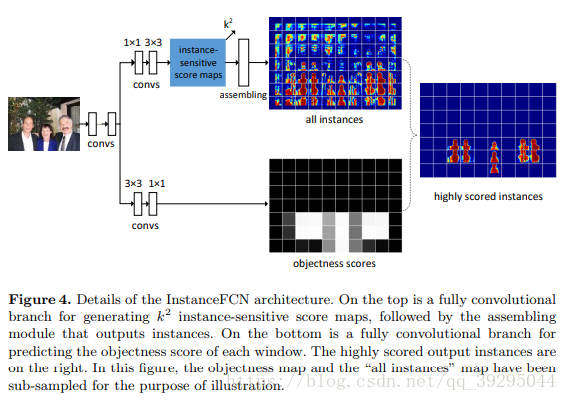
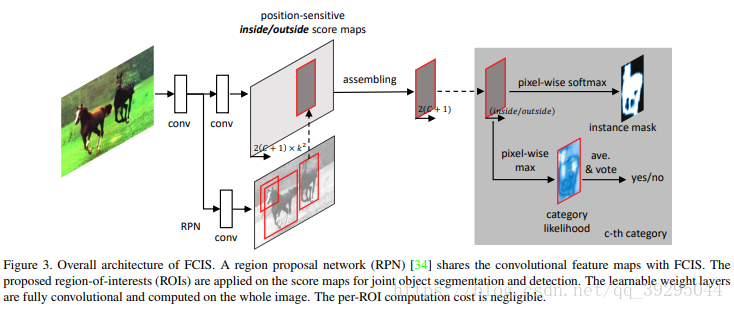
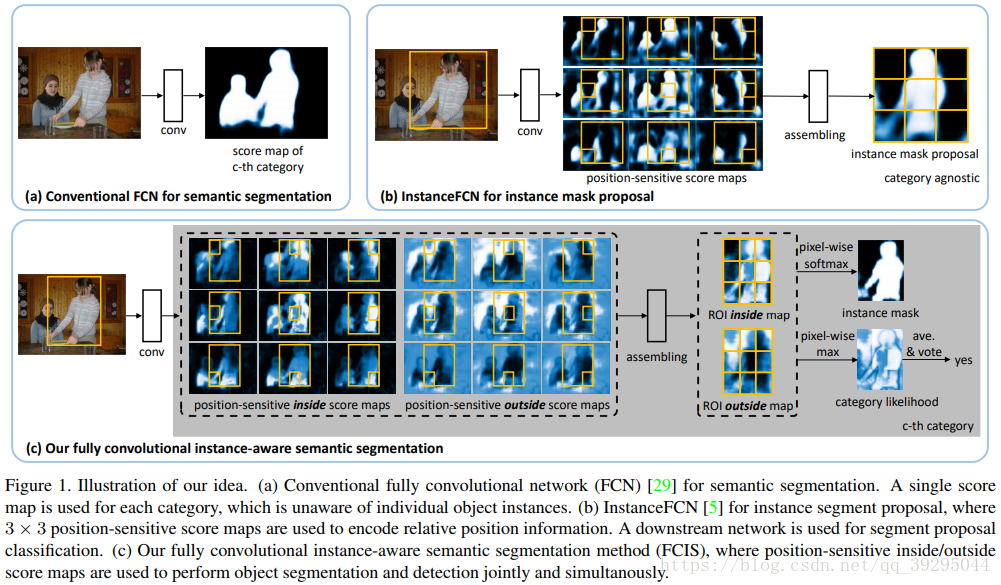
实例分割:机器自动从图像中用目标检测方法框出不同实例,再用语义分割方法在不同实例区域内进行逐像素标记 借一个浅显的说法:语义分割不区分属于相同类别的不同实例。例如,当图像中有多只猫时,语义分割会将两只猫整体的所有像素预测为“猫”这个类别。与此不同的是,实例分割需要区分出哪些像素属于第一只猫、哪些像素属于第二只猫 基本思路 目标检测+语义分割。 SDS->HyperColumns->CFM->Deep&Sharp Mask->MNC->ISFCN->FCIS->SIS->Mask RCNN->PAN SDS: MCG+AlexNet+SVM+NMS 改进: MCG代替SS提取region,用bottom-up分割出的结果,然后把region以及由它组合成boundingboxes来同时优化two-path 的网络 特征提取中不是在两条通道上使用同一网络,而是单独训练这两条路径 1、建议生成:通过MCG算法为每个图像生成2k个候选区域 2、特征提取:联合训练两个网络,从区域bbox和区域前景提取特征 3、区域分类:基于CNN最后的特征训练SVM去分每个类别 4、区域改良:对许多重复覆盖的区域进行非最大压制(NMS) 提取特征网络结构: HyperColumns: 基于SDS基础,在分类器中引入超列的概念,实现对ROI的修正 针对SDS的第三步改进:基于CNN最后的特征训练SVM去分类->基于高、低层特征融合形成Hypercolumns训练SVM Hypercolumns结构: 把低层特征和高层特征结合一起,用于分类,改善对细节的探测 CFM: Convolutional Feature Masking 动机:SPP两个作用:1)通过矩形框生成特征图的掩码Mask 2)把任意大小的区域生成一个固定大小的特征 引入CFM代替矩形框,用不规则区域生成掩码Mask,提取特征 图像掩码 Mask:用选定的图像、图形或物体,对处理的图像(全部或局部)进行遮挡,来控制图像处理的区域或处理过程。 通过卷积特征提取掩码而不是原始图像中提取 CFM引入网络的两种方案: 在最后卷积特征引入CFM or 在SPP中引进CFM Deep Mask & Sharp Mask & Multipath Net: 这里看到一篇比较好的总结,转载一下 Facebook的物体分割新框架研究 MNC: 改进: 用3个任务形成一个级联结构,并共享底层卷积特征 1、回归边框级实例(Regressing Box-level Instances):采用RPN来预测无分类的bounding box位置和评分 2、回归掩码级实例(Regressing Mask-level Instances): 用第一阶段的卷积特征还有bbox作为输入,通过ROIpooling提取特征,加上两个FC层,一是降维,二是回归像素级掩码,得到输出是每一个候选box的像素级语义掩码(DeepMark类似,但因共享特征而节约开销) 3、实例分类(Categorizing instances):共享特征、阶段一bbox、阶段二Mask作输入,最后输出每一个实例的分类得分 这个网络当中,每个阶段都会激活损失函数,但后阶段的损失函数依赖前阶段的输出 ISFCN: 改进: 针对局部的像素进行改善。FCN中,训练一个classifier来预测一个像素属于某个物体类的得分,它是平移不变而且无法区分单个物体实例的。比如,同样的一个像素,既可以是物体1的前景也可以是相邻物体2的背景,两个物体属于同一类,那么FCN产生的每个类只有一个score,是没有办法区分这两种情况的。所以,提出了positive-sensitive score map,每个score表示一个像素在某个相对位置上属于某个物体实例的得分(R-FCN的position sensitive score map思路用到instance上) 1、CNN特征提取,(用vgg16改造)减少网络步长和增加特征图的分辨率,提取效果更好的特征图 2、顶层特征作为两个全卷积分支的输入,一个用于预估部分实例,生成了instance-sensitive score maps(下图上分支的蓝色框);另一个对对象评分,每个像素通过逻辑回归对以该像素为中心的滑动窗口的实例/非实例进行分类,生成对象评分图 instance-sensitive score maps 和 positive-sensitive score map差不多(可以看看目标检测总结中R-FCN的说明) FCIS: 改进: 继续采用Instance-sensitive score maps,加了区分在物体实例内还是外的inside/outside score maps,引入一点context信息;操作是在box proposal上进行,代替了在滑动窗口操作 1、CNN特征提取,在第4卷积层加上RPN生成300个ROI,另Bbox分支再生成300个ROI,空洞算法处理第5卷积层,然后在第5卷积层生成position-sensitive in/out score map 【位置敏感分数图参数化(Position-sensitive Score Map Parameterization):使用单独的下游网络将候选mask进一步分辨对象类别】 2、通过组装操作(assembling)前面得到的ROI生成像素级的得分图,主要目的是1)检测:检测ROI的每一像素是否属于目标Bbox相关的位置上(检测到对象与否); 2)分割:ROI的每一像素是否在对象实例的边界内【联合掩码预测和分类(Joint Mask Prediction and Classification)】 3、端到端处理(End to End Solution):softmax操作生成前景可能性,最大化操作生成每一像素的对象分类,最后用平均池化推断分类得分
SIS: 采用端到端全卷积进行实例感知语义分割,把底层卷积结果和scoremap完全共享于预测和分类的子任务,通过一个无额外参数的新联合方程实现 1、CNN特征提取,用ResNet模型,第4卷积层加上RPN,空洞算法处理第5卷积层,通过融合多尺度及多分区模式生成生成position-sensitive in/out score map(如图二),并第5卷积层添加 新的语义分割子网络生成C+1 score map(C+1种分类可能) 2、贝叶斯推断,提高了分割和分类的准确性 3、softmax操作生成前景可能性,最大化操作生成每一像素的对象分类,最后用平均池化推断分类得分
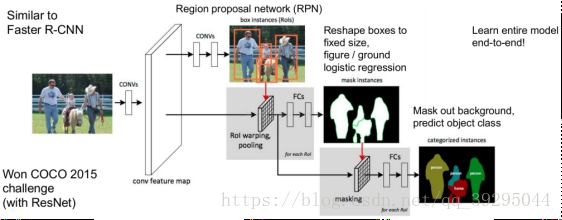
Mask R-CNN: 改进: 用FPN进行目标检测,并通过添加额外分支进行语义分割(额外分割分支和原检测分支不共享参数),即MaskR-CNN有三个输出分支(分类、坐标回归、和分割) (1).改进了RoIpooling,通过双线性差值使候选区域和卷积特征的对齐不因量化而损失信息。 (2).在分割时,MaskR-CNN将判断类别和输出模板(mask)这两个任务解耦合,用sigmoid配合对率(logistic)损失函数对每个类别的模板单独处理,比经典分割方法用softmax让所有类别一起竞争效果更好 1、整张图片送入CNN,进行特征提取 2、在最后一层卷积featuremap上,通过RPN生成ROI,每张图片大约300个建议窗口 3、通过RoIAlign层使得每个建议窗口生成固定大小的feature map(ROIAlign是生成mask预测的关键) 4、得到三个输出向量,第一个是softmax分类,第二个是每一类的bounding box回归,第三个是每一个ROI的二进制掩码Mask(FCN生成)
Mask Representation: mask 编码了 输入的 object 的空间布局(spatial layout) 针对每个 RoI,采用 FCN 预测一个 m×m 的 mask. mask 分支的每一网络层均可保持 m×m 的 object 空间布局,而不用压扁拉伸成向量形式来表示,导致空间信息损失. pixel-to-pixel 操作需要保证 RoI 特征图的对齐性,以保留 per-pixel 空间映射关系(映射到ROI原图). 即 RoIAlign. ROIAlign: 原来RoIPooling是映射原图RoI 到特征图 RoI,其间基于 stride 间隔来取整,导致将特征图RoI映射回原图RoI时,出现 stride 造成的误差(max pool 后特征图的 RoI 与原RoI 间的空间不对齐更加明显). 会影响像素级的 mask 分割. 因此需要像素级的对齐ROIAlign RoIPool 用于从每个 RoI 中提取小的特征图的操作,RoIPool 选择的特征图区域,会与原图中的区域有轻微出入,分析ROIpool的步骤:把浮点数ROI量化到离散粒度的特征图,细分为空间直方图的bins,最后每个bin所涵盖的特征值被聚合(常用max pooling聚合) 也就是说,对浮点数 RoI 量化,再提取分块的直方图,最后利用 max pooling 组合,导致 RoI 和提取的特征间的 misalignments。对于平移不变性的分类任务影响不大,但对于要求精确的像素级 masks 预测具有较大的负影响. RoIAlign 能够去除 RoIPool 引入的 misalignments,准确地对齐输入的提取特征. 即: 避免 RoI 边界或 bins 进行量化(如,采用 来替代 [四舍五入处理] );采用 bilinear interpolation 根据每个 RoI bin 的四个采样点来计算输入特征的精确值,并采用 max 或 average 来组合结果. 如,假设点 ,取其周围最近的四个采样点,在 Y 方向进行两次插值,再在 X 方向 进行两次插值,以得到新的插值. 这种处理方式不会影响 RoI 的空间布局. 假设有一个 128x128 的图像,25x25 的特征图,想要找出与原始图像左上角 15x15 位置对应的特征区域,怎么在特征图上选取像素?  原始图像的每一个像素与特征图上的 25/128 个像素对应. 为了在原始图像选取 15 个像素,在特征图上我们需要选择 15 * 25/128 ~= 2.93 个像素. 对于这种情形,RoIPool 会舍去零头选择两个像素,导致排列问题. 但在 RoIAlign,这种去掉小数点之后数字的方式被避免,而是使用双线性插值(bilinear interpolation)准确获得 2.93 像素位置的信息,避免了排列错误.
网络结构Backbone 卷积网络 —— 用于整张图片的特征提取 ,ResNeXt-101,ResNet-50,FPN(Feature Pyramid Network).
Head 网络 —— 用于对每个 RoI 分别进行 bounding-box 识别(分类和回归) 和 Mask 预测.
PAN: 1、整张图片送入FPN,进行特征提取 2、自下到上的通道增强将低层的信息融入高层,生成新的特征图 3、经过适应特征池化层 4、输入两个分支,得到三个输出向量,一是softmax分类&Bbox回归,二是每一个ROI的掩码Mask(FC融合)
Bottom-up 路径增强: 为了加强低层信息变得更容易传播,细节利用上
Adapting 特征池: 允许每个候选区从访问各级信息进行预测。 FPN中,从P2-P6(P6仅用作生成proposal,不用作RoIPooling时提取特征)多尺度地生成proposal,然后做RoIPooling时会根据proposal的大小将它分配到不同的level去crop特征,小的proposal去low-level的层,大的proposal去high-level的层。 这样做虽然简单也蛮有效,但它不是最好的处理方式,尽管P2-P5(N2-N5)已经融合了low-level和high-level的特征,然后它们的主要特征还是以它本有的level为主 重要的特征与所在的层无关,如果小的proposal能从high-level层获取到更多的上下文语义信息和较大识别域是有利于它分类的,而大的proposal能从low-leve层获取到更好的细节是有利定位准确性的 因此,打算每个proposal从所有level的特征上做RoIPooling,然后在后面融合,融合的阶段和方式都可实验,比如分类时是两个fc,这个融合阶段可以是fuse,fc1, fc2或者fc1, fuse, fc2,融合策略可是sum也可以是max,最后证明fc1, fuse,fc2和max最好。这个改进是增加些运算负担。
FC融合: MaskRCNN中Mask分支就是个简版的fcn,fcn是全卷积网络,它根据一个局部的视野域来预测,且参数是全图共享,而全连接fc是全图视野域对位置更敏感,看得更大,这一点large kernel也间接证明了大视野域的作用。因此,这里打算多加一条用全连接层预测的支路来做mask预测,然后和fcn融合,具体做法如下图所示,至于conv4_fc接在fcn支路哪一个卷积后后面融合,,实验对比,conv3后面结果更好一点。 |
|
|