|
简介:本篇文章主要针对一些对网络爬虫感兴趣的初学者,快速让你们入门分布式网络爬虫架构,这篇文章以草根网为例,大家准备好电脑跟着我一步一步走,相信花个一天的时间能对分布式与爬虫有个很好的认识,下面我们就开始了!
安装
1 scrapy
$ sudo pip install scrapy
ps.scrapy安装对于不同的环境配置都会有不同,这里我很难给出一个详细的教程,大家根据自己的情况Google一下或者我这里推荐一些我认为不错的
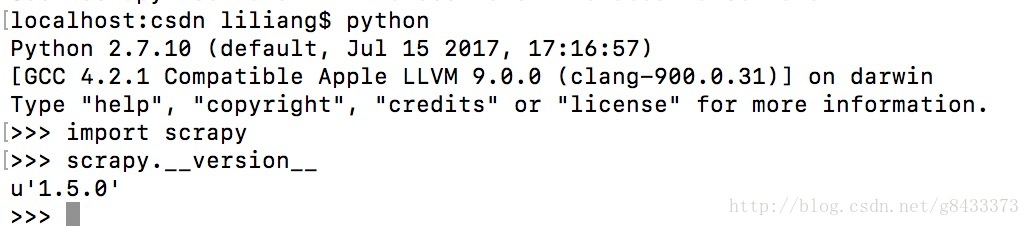
安装好之后打开python界面输入
import scrapy
scrapy.__version__
,如果安装成功应该会出现如下界面:
2 redis安装:
$ sudo apt-get install redis-server
ps.redis安装可以参考这里
3 scrapy-redis安装:
$ sudo pip install scrapy-reids
4 mysql安装:
请参考这里,本例中使用的是MySQL5.6.38版本
5 sqlalchemy和PyMySQL安装:
$ sudo pip install sqlalchemy
$ sudo pip install PyMySQL
6 git安装:
7 其他:
实战
上面安装和配置完后,我们先把项目跑起来再说,具体的细节和流程我们后面讲,下面进入正题:
1 在某个地方建立一个文件夹,放我们需要需要的项目,假设这个文件夹名称是caogen_pjt,后面都会用这个说。
2 打开终端,进入caogen_pjt 文件夹,我们这里需要从git上clone 两个项目文件(master和slaver)下来:
$ git clone https://github.com/MrPaoBrother/caogen_master.git
$ git clone https://github.com/MrPaoBrother/caogen_slaver.git
成功后,如下图:
ps. 如果有基础的朋友直接按照git上的README.md 走就行,这篇文章只针对入门级别的朋友。
3 我们首先运行caogen_master这个项目,我们进入caogen_master/run_master.py文件,如果上面都配置好了,直接运行该文件即可:
$ python run_master.py
ps. 如果有scrapy基础的朋友,直接用命令scrapy crawl caogen_master运行也行
运行完成后,我们查看控制台和redis数据库,如下图:

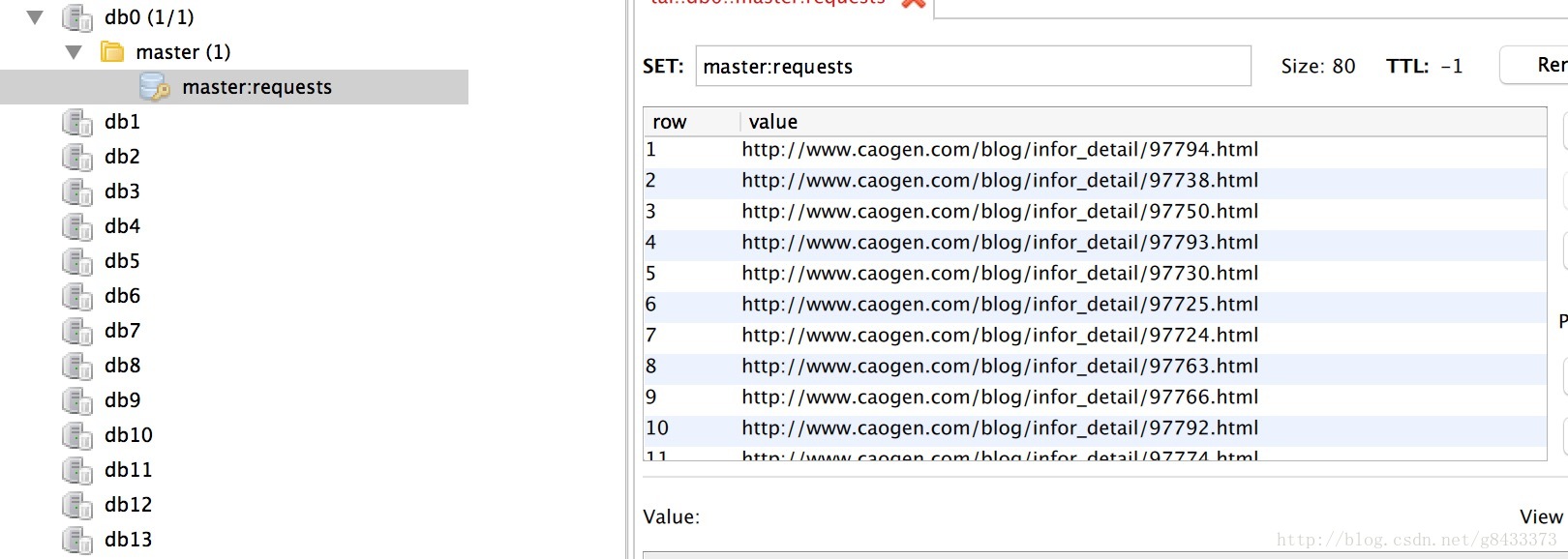
ps. 简单的来说我们已经完成了发布任务的过程,爬虫过程中url就相当于老板发布的任务,那么下面就需要员工来接收并且执行。
4 下面我们进入caogen_slaver项目中,同样,我们直接进入到caogen_slaver/run_slaver.py 文件中,直接运行或者终端输入:
$ python run_slaver.py
slaver你可以理解为员工,员工的工作就是等待老板发布任务,上面步骤3中老板已经发布了任务了,那么运行后我们可以看到redis数据库中多了一些item,如图:
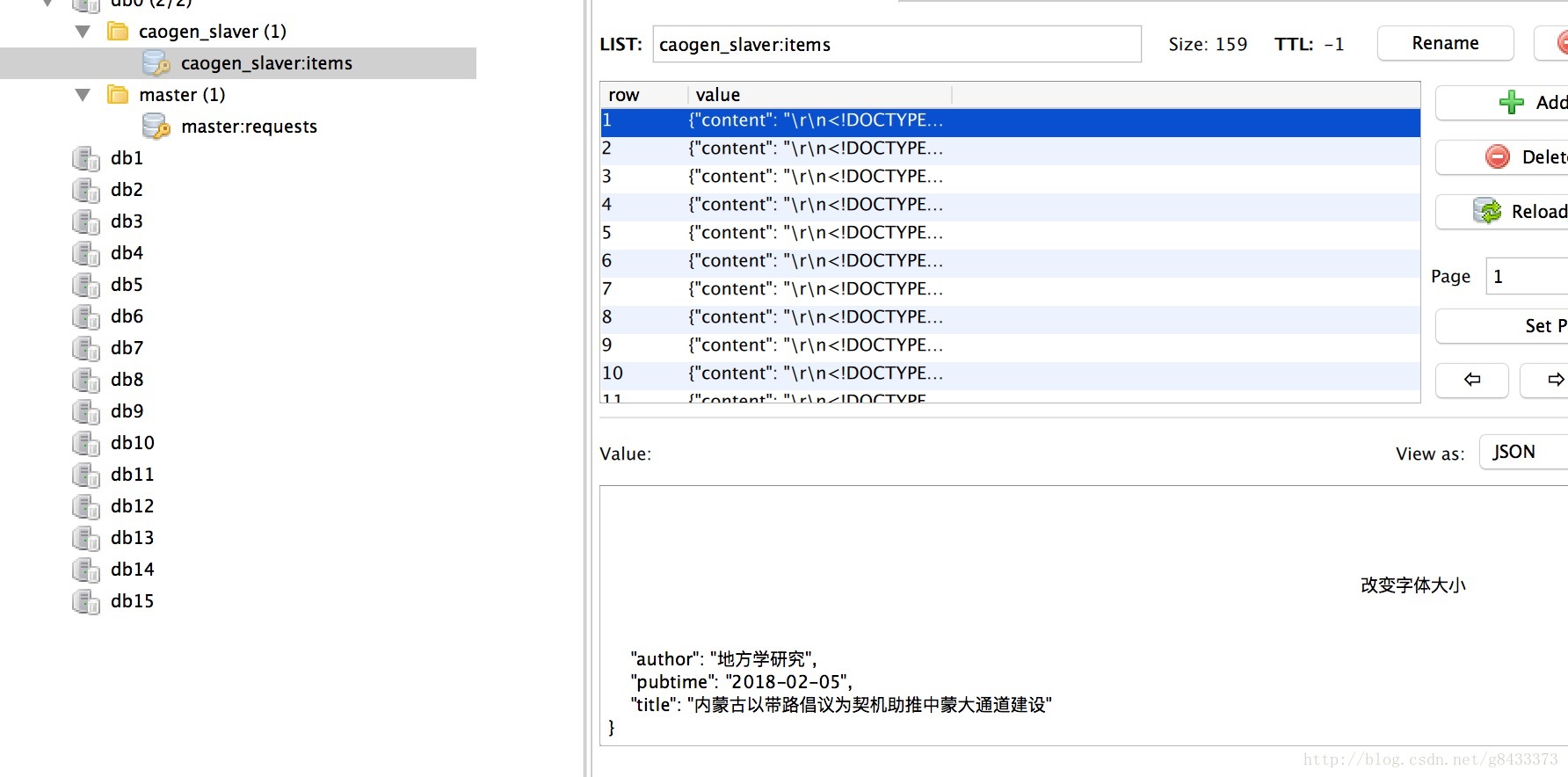
- ps. 这些
item 我们可以理解为员工做完任务后出的成果,成果当然都是老板的了,哈哈,所以把成果都放到redis 里面等待老板去取。
5 现在老板要做的就是回收员工的成果,所以我们回到caogen_master 文件中,找到caogen_master/process_item.py文件,终端运行:
$ python process_items.py caogen_slaver:items -v

- ps. 很稳,老板已经把员工的成果全部收入囊中了,那么这样一套下来,恭喜你,你已经入门了分布式网络爬虫,那么下面我来详细的讲解一下其中的原理和项目中的一些关键代码。如果没有跑通项目,没关系,先看一下后面的理论部分和注意事项可能会解决你的问题。
理论部分
分布式的流程
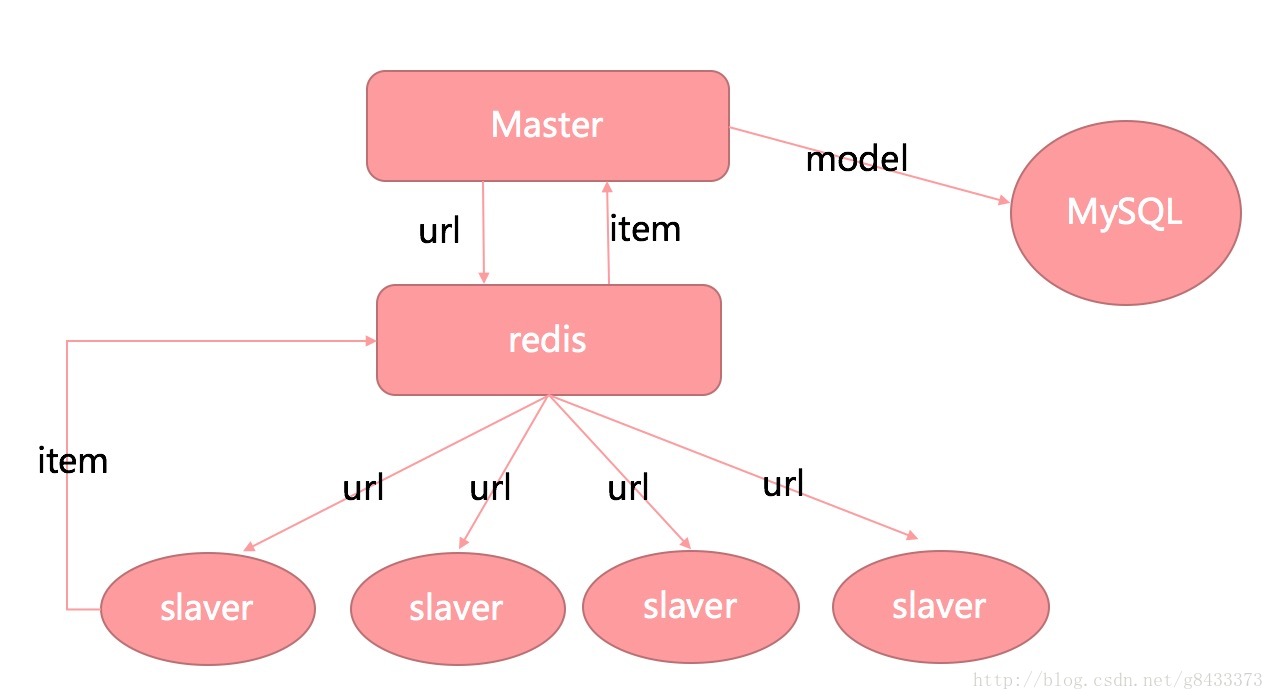
Master->老板
url->任务
redis->存放任务和接收成果的仓库
slaver->员工
item->员工执行任务后的成果
MySQL->老板的小金库
1. 老板master先发放任务给仓库redis。
2. 员工slaver从仓库redis中取出任务去执行。
3. 员工slaver做完了事后把成果放回仓库redis。
4. 老板master 只需要一直等待收获成果item就行,然后把成果item 存入自己的小金库MySQL。
- 项目中就这四个步骤依次循环,这就是一个简单的分布式爬虫的基本流程,那么下面我来简单的介绍下项目中的关键文件和核心代码
项目文件简介
- 我们先看
caogen_master中的文件结构,如图:
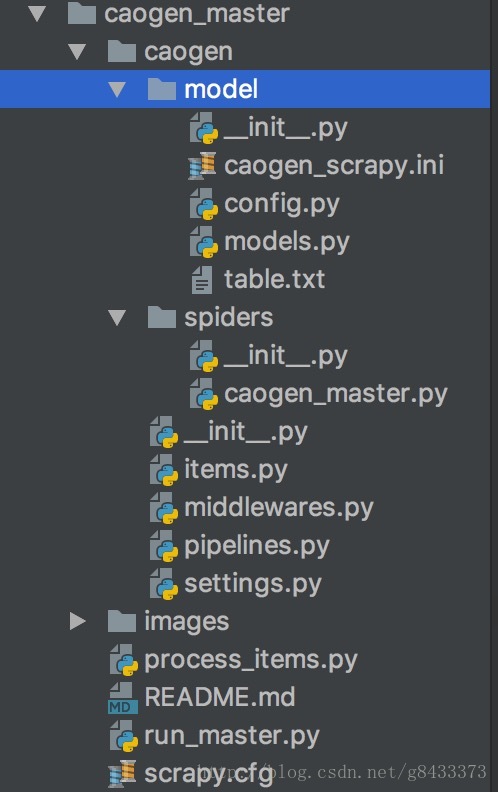
> model/caogen_scrapy.ini : 配置mysql和redis的连接信息
config.py: 根据上面的配置信息,提供实例接口
models.py: 存放一些模型对象,例中存放的是文章详情ArticleDetail
table.txt: 存放一些建表语句,使用mysql的朋友直接运行语句就能建表。
> spiders/__init__.py : 这个不用管,你只要知道作者是power就行了,哈哈。
caogen_master.py : 这是项目的核心文件,也就是master爬虫文件,后面会细说。
> caogen/items.py: 相当于把信息封装成一个实体传输,项目中对应的就是ArticleDetailItem。
middlewares.py : 中间件文件,这个了解一下就行。
pipelines.py : 管道文件,主要就是处理传来的item,这里用到的是scrapy-redis框架中自带的pipeline。
settings.py : 设置文件,具体的查看后面的相关资料。
> caogen_master/process_items.py : 这就是老板把成果放入小金库的文件,后面会有代码详解。
run_master.py : 启动项目的入口文件,方便运行。
- 同理,
caogen_slaver的文件结构也和master差不多,读者自行分析。
核心代码
# caogen_master/caogen/spiders/caogen_master.py
def send_to_redis(self, key='master:requests', value=None):
"""
将request请求放进redis
:param key:默认master服务器
:param value:url以及一些别的附带的信息
:return:
"""
print value
print type(value)
self.redis_conn.sadd(key, value)
print "Success send to Redis!"
# caogen_master/caogen/spiders/caogen_master.py
def start_requests(self):
while True:
url = self.get_msg_from_redis()
if url:
yield scrapy.Request(url, headers=self.headers, callback=self.parse, dont_filter=True)
else:
print("Redis 数据库为空,5秒后继续监测...")
time.sleep(5)
- 其中
get_msg_from_redis函数就是从redis中pop一条url出来。
# caogen_slaver/caogen/settings.py
'''
启用scrapy-redis组件
'''
# Enables scheduling storing requests queue in redis.
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# Ensure all spiders share same duplicates filter through redis.
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# Configure item pipelines
# See http://scrapy./en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 300
}
- 这里是通过配置文件
SCHEDULER= "scrapy_redis.scheduler.Scheduler"和'scrapy_redis.pipelines.RedisPipeline': 300 使用了scrapy-redis框架中的 Scheduler和pipeline,查看scray-redis源码可以发现:
# scrapy-redis源码中的pipelines.py
def _process_item(self, item, spider):
key = self.item_key(item, spider)
data = self.serialize(item)
self.server.rpush(key, data)
return item
# scrapy-redis源码中的scheduler.py
def enqueue_request(self, request):
if not request.dont_filter and self.df.request_seen(request):
self.df.log(request, self.spider)
return False
if self.stats:
self.stats.inc_value('scheduler/enqueued/redis', spider=self.spider)
self.queue.push(request)
return True
这里可能有点难,没关系,就过一下就行,整体的思路把握住了最重要。
# caogen_master/process_item.py
while processed < limit:
# Change ``blpop`` to ``brpop`` to process as LIFO.
ret = r.blpop(keys, timeout)
# If data is found before the timeout then we consider we are done.
if ret is None:
time.sleep(wait)
continue
source, data = ret
try:
item = json.loads(data)
except Exception:
logger.exception("Failed to load item:\n%r", pprint.pformat(data))
continue
try:
"""
处理item
"""
process_item(item)
# logger.debug("[%s] Processing item: %s <%s>", source, str(title), str(image_path))
logger.debug("[%s] Processing item", source)
except KeyError:
logger.exception("[%s] Failed to process item:\n%r",
source, pprint.pformat(item))
continue
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 这一段意思就是老板一直在等待仓库中是否有成果,有的话就
process_item这个成果,将他放入小金库MySQL。
ps. 里面很多函数名是重写scrapy框架里面的,所以函数名是固定的,这里我不讲scrapy的内部原理,详细的可以参考后面的相关资料进行学习。
注意事项
1 这里之所以选择草根网是因为针对入门级的朋友来说在网站的分析方面时间成本很少,且静态网站不怎么更新DOM结构,对于一些刚入门的人来说会更容易接受一些。
2 如果项目运行中缺少什么模块,请自行根据报错信息安装,这里不可能给出全部的可能。
3 项目中没有设置一些中间件,只是单纯的展示一遍分布式爬虫的基本流程,有兴趣的朋友可以自己增加一些中间件比如设置代理,设置User-Agent等。
4 如果项目中在运行时有什么bug,请留言。
5 该项目要master端和slaver端一起运行才能展示效果,请注意。
6 该项目重点是了解分布式的爬虫流程,具体的爬虫细节以及架构的内部原理请参考下面给出的相关资料进行学习。
7 所有的文档都没有框架源码阅读更加详细,有兴趣的读者可以花时间通读一遍scrapy和scrapy-redis的源码,会更有帮助。
总结
相信大家对分布式爬虫有了一个新的认识,其实一点也不难,这样做的好处就是减轻主服务器的压力,并且增加了项目的可拓展性。
网络爬虫到后面更多的是分析网站,比如一些加密参数的运行分析,抓包找接口,等等,大家如果有兴趣可以试着去爬淘宝,头条,微信等一些网站,我前几天也写了一个关于网易云音乐评论的信息抓取,就涉及一些加密参数需要解析才能获取真实接口。
后续应该有时间还会继续带来更加精彩的教程!
|














