hadoop:
- 开源分布式平台
- 核心:HDFS、MapReduce
- HDFS在集群上实现分布式文件系统
- MapReduce在集群上实现分布式计算和任务处理
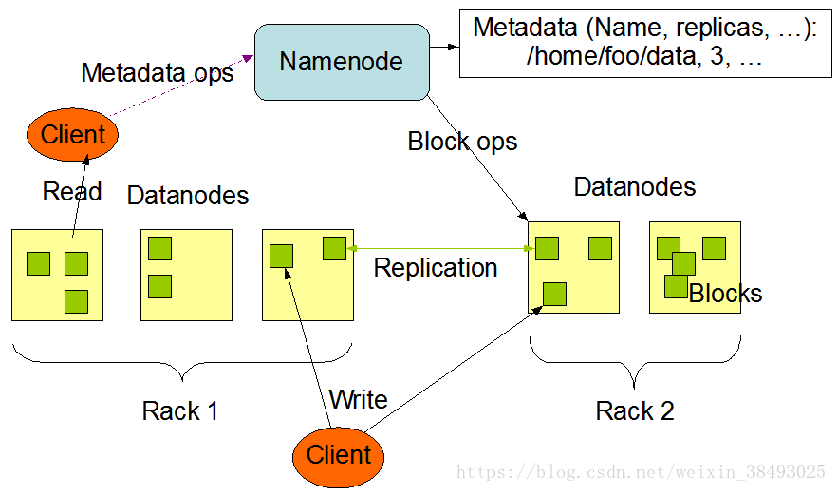
1 HDFS体系结构
一个HDFS集群是由一个NameNode和若干个DataNode组成。
- NameNode(名字节点):管理文件系统的命名空间和客户端对文件的访问操作
(1)执行文件系统的命名空间操作,如打开、关闭、重命名文件或目录
(2)负责数据块到具体DataNode的映射
- DataNode(数据节点):管理存储的数据
(1)负责处理文件系统客户端的文件读写请求
(2)在NameNode的统一调度下进行数据块的创建、删除和复制工作
2 MapReduce体系结构
MapReduce框架是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。
- JobTracker:调度和管理其他TaskTracker
- TaskTracker:负责执行任务 ,运行于DataNode之上
3 MapReduce任务处理流程
思想:分而治之
- 用户自定义的Map函数把输入的键值对映射(map)成一组新的键值对
- MapReduce把所有具有相同的key值的value集合一起,传递给Reduce函数
- 用户自定义的Reduce函数对相同key下的所有value进行处理再输出最终的键值对
4 MapReduce应用案例
4.1 单词计数
解决方案
- 将文件内容切分为单词
- 将所有相同的单词聚集在一起
- 计算单词出现的次数并输出
设计思路
- map阶段:完成由输入数据到单词切分的工作 <行号,内容> --> <word,1>
- reduce阶段:接收所有单词并计算其频数 <word,{1,1,…}> --> <word,sum>
4.2 数据去重
解决方案
- 将文件内容切分为单词
- 将所有相同的单词聚集在一起
- 接收元组,直接输出key
设计思路
- map阶段:完成由输入数据到单词切分的工作 <行号,内容> --> <word,1>
- reduce阶段:接收单词并直接输出键 <word,{1,1,…}> --> <word,NAN>
4.3 数据排序
解决方案
- 利用hadoop自带的排序
- 将数据转为IntWritable类型
- hadoop自动对所有的元组进行基于Key的排序
- 接收元组,直接输出key,根据输入value-list中的元素个数决定key的输出次数
设计思路
- map阶段:将输入的value转为IntWritable类型,作为输出的key <行号,data> --> <data,1>
-
- 自定义partition函数:
(1)注意:reduce自动排序仅仅是发送到自己所在节点的数据,使用默认的排序不能保证全局顺序
(2)根据输入数据的最大值和mapreduce框架中partition的数量获取将输入数据按照大小分块的边界,然后根据输入数据和边界的关系返回对应的partition ID
- reduce阶段:将输入的key复制到输出的value上,根据输入value-list中的元素个数决定key的输出次数,用全局linenum代表key的位次 <data,{1,1,…}> --> <linenum, data>
4.4 单/多表连接
解决方案
- 区分输入行是左表还是右表,然后对两列值进行分割,连接列保存在key中,其他列和左右表标识保存在value中
- 解析map输出,将value中数据按照左右表标识分别保存,求笛卡尔积并输出
设计思路
- map阶段:识别出输入的行属于哪个表后,对其进行分割,将连接的列值保存在key中,另一列和左右表标识保存在value中,然后输出<行号,行数据> --> <连接列值,其他列值和左右表标识>
- reduce阶段:拿到连接结果后,解析value内容,根据标识将左右表内容分开存放,求笛卡尔积最后直接输出 <连接列值,{其他列值和左右表标识,其他列值和左右表标识,…}> --> <连接列值,左表其他列值和右表其他列值的笛卡尔积>
|













