|
本文来自OPPO互联网技术团队,如需要转载,请注明出处及作者。 Parker 是 OPPO 互联网自研的一个基于 RocksDB 的分布式 KV 存储系统,它是一款类 Redis 的存储系统,主要解决的是用户使用 Redis 遇到的内存超限启动恢复时间长,一主多从代价大,硬件成本昂贵,无法存储海量数据等问题。 1. Parker简介Parker 具有如下特性:
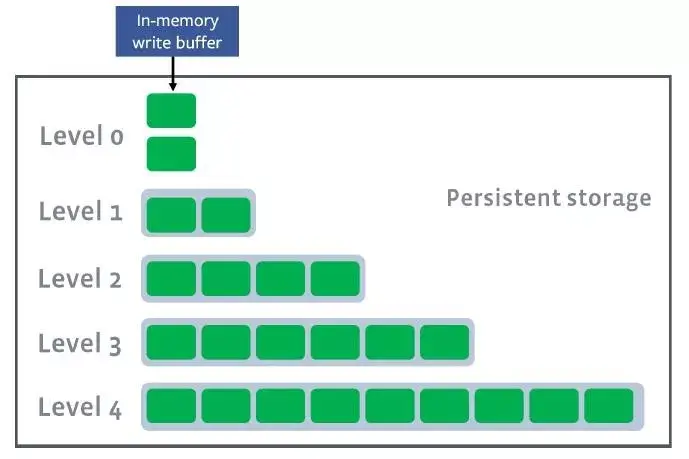
2. 遇到问题我们在容量为 5TB 的存储服务器上部署了 8 个 Parker 实例,写入的数据设置为 3 天过期,预计在数据写入速度和过期回收速度平衡的情况下,单实例会保持有 300GB 的存储占用。 实际上 Parker 运行五天后发现磁盘使用率不断攀升,开始写入的前三天,磁盘使用率直线上升,而后虽然上升速度有所减缓,但是总体上升速度还是比较快,与预期效果有严重偏差。虽然数据在 TTL 过期之后无法读取到,但是实际上磁盘空间并没有得到及时回收,这导致磁盘使用率居高不下。 3. 原因分析3.1 RocksDB 原理Parker 的底层存储引擎使用的是 RocksDB ,RocksDB 底层数据存储是 LSM 架构。数据分为不同的层,默认是 7 层,compaction styles 默认选择 leveled compaction。如下图所示: 用户写入数据到 RocksDB 时,会先将数据写入到一个 Memtable 中,当一个 Memtable 写满了之后,就会变成 immutable 的 Memtable。RocksDB 在后台会通过一个 flush 线程将这个 Memtableflush 到磁盘,生成一个 Sorted String Table (SST) 文件,放在 Level 0 层。当 Level 0 层的 SST 文件个数超过阈值之后,就会通过 compaction 策略将其合并到 Level 1 层,以此类推。 如果没有 Compaction,那么写入是非常快的,但这样会造成读性能降低,同样也会造成很严重的空间放大问题。为了平衡写入、读取、空间三者的关系,RocksDB 会在后台执行compaction,将不同Level 的 SST 进行合并。 3.2 TTL实现原理RocksDB 中有一个 CompactionFilter 功能,该功能就是 RocksDB 在 compaction 每一条数据时,都会调用一个 Filter 函数 ,这是一个钩子函数,可以用户自定义。TTL 的实现方法就是在 Filter 函数中实现 TTL 过期删除逻辑,具体实现如下所述:
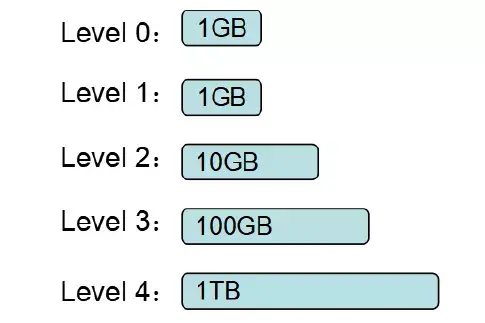
3.3 问题分析Parker 中配置 RocksDB 每一层存储的容量上限如下: 仔细梳理 RocksDB 的 compaction 原理:RocksDB 触发 leveled compaction 的条件是该层文件大小或个数超过上限,例如 Level 2 的文件总大小超过 10GB,则会触发 compaction,从而调用compaction fliter,过滤掉 TTL 过期的数据。 基于我们遇到的问题,结合 RocksDB 的原理进行分析,我们发现:在我们的场景中会有 380GB 左右的数据会落在 Level 4,而这些数据虽然大部分已经过期,但由于这一层的数据一直没能达到该 Level 容量的上限 1TB,所以未触发 compaction filter,所以造成过期数据没有被删除,磁盘空间回收不了。 4. 解决方案简单的更改 RocksDB 的配置,使得每一层存储的容量上限变小,可以解决上述问题,但是这种方案并不具备普适性。不同的使用场景,不同的存储数据量,存储数据量一旦改变就需要重启服务来更改RocksDB 的配置,这是业务不可接受。 从宏观上分析,回收过期数据磁盘空间的方案主要有两类:
为了实现快速回收磁盘空间删除过期数据,我们结合 RocksDB 的原理,梳理出了以下的几种方案: 4.1 业务实现删除逻辑通过 Parker 自身逻辑,来主动删除过期数据。业内有赞 KV 就是采用类似的方案。具体做法是,保持现有存储列族不变,另外增加一个列族,专门存储 key 的 TTL,然后通过一个 goroutine 根据当前时间戳,按照过期数据删除策略可以是定时触发,例如凌晨1点,或者每个一段时间触发等。该列族中 key 的编码规则如下:
这个方案优点是回收速度快且回收时间可控,但是缺点就是实现复杂,极端情况下会降低 50% 的TPS。 4.2 OpenDbWithTTL 方案这个是 RocksDB 本身支持的一种数据过期淘汰方案,该方案是通过特定的 API 打开 DB,对写入该 DB 的全部 key 都遵循一个 TTL 过期策略,例如 TTL 为 3 天,那么写入该 DB 的 key 都会在写入的三天后自动过期。该方案底层也是通过 compaction filter 实现的,也就是说过期数据虽然对用户不可见,但是磁盘空间并不会及时回收,另外该方案不灵活,无法针对每一条 key 设置 TTL。 4.3 主动触发 RocksDB 的 compaction目前空间无法快速回收的根本原因就是数据堆积在某一层,而该层没有触发 compaction,那么我们可以手动调用 RocksDB 的 CompactionRange 函数,来触发 compaction filter,达到快速回收磁盘空间的目的。但是主动调用 CompactionRange 会导致 RocksDB 自身的 compaction 暂停,这会触发 Write Stall,造成非常严重的后果,所有这种方案也不是非常完美。 4.4 Periodic compaction + dynamic compactionPeriodic compaction 的主要原理是增加一个 periodic_compaction_seconds 参数,并记录每个SST 文件的创建时间,每隔 periodic_compaction_seconds 秒,主动对这个 SST 文件进行 compaction 操作,从而回收沉底的 SST 文件;而 dynamic compaction 则是通过设置level_compaction_dynamic_level_bytes 为 true,进行动态合并,而不是按 level 的顺序合并到下一层,这使得 compaction 更加频繁。这个方案实现方式比较优雅,无须改动现有代码结构,只需要改动一些配置即可。 对以上几个方案进行比较,方案 4 实现较为完美,对实现逻辑改动较小,于是我们对方案 4 进行了实验验证。 5. 实验验证5.1 机器配置
5.2 RocksDB 新增配置
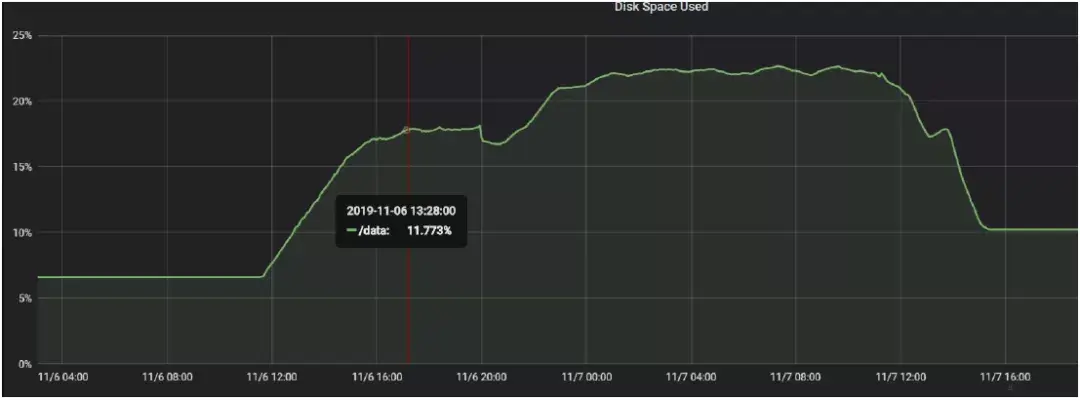
5.3 测试结果我们向 Parker KV 存储写入字符串数据:总写入数量:30000000000(三百亿)条数据,单条数据170Byte 左右。每条数据的过期时间为写入时间之后的 10800s,即写入 3 小时后过期,写入速度为51MB/s,写入总量预估为 5.32T。该机器磁盘占用情况如下: 5.4 结果分析
6. 总结目前来看,通过 periodic compaction + TTL 过期来回收磁盘空间的方案是可行的,并且我们总结出如下规律: 通过监控发现 periodic compaction 对 CPU 负载有一定影响,也就是说periodic_compaction_seconds 时间越短,CPU 负载越高。其实这也容易理解:RocksDB 更加积极主动的进行 SST 文件的 compaction,必然会消耗更多的 CPU 资源,建议将这个参数调整为12 小时。 从理论上推导,整个 RocksDB 中会有约 periodic_compaction_seconds 时间长度的过期数据延迟回收,从而造成一定的空间放大,所以部署的时需预留有一定的空闲磁盘空间,建议预留 30%的冗余存储空间。 7. 参考资料
|
|
|