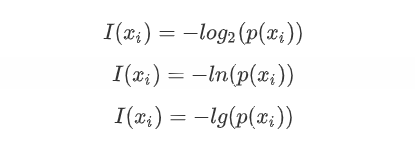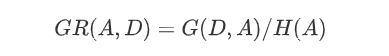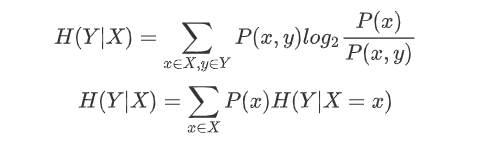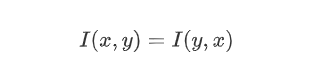from sklearn.feature_extraction import DictVectorizerfrom sklearn import treefrom sklearn import preprocessingfrom six import StringIOimport csvimport sysclass MyTree:def __init__(self):# 处理特征使用的对象self.vec = DictVectorizer()# 处理标签使用的对象self.lb = preprocessing.LabelBinarizer()
self.reader, self.headers = MyTree.load_data()
self.feature_list, self.label_list = self.create_feature_array()
self.clfPlay = self.clf_play()
self.visualize_model()# 加载数据 @staticmethoddef load_data():
elem_data = open(r"./dataset.csv")
reader = csv.reader(elem_data)
headers = reader.__next__()return reader, headers# 构建特征矩阵和标签向量def create_feature_array(self):
feature_list = []
label_list = []for row in self.reader:
label_list.append(row[len(row)-1])
row_dict = {}for i in range(1, len(row)-1):
row_dict[self.headers[i]] = row[i]
feature_list.append(row_dict)return feature_list, label_list# 向量化特征数据def feature_vectorization(self):
dummy_x = self.vec.fit_transform(self.feature_list).toarray()return dummy_x# 向量化标签数据def label_vectorization(self):
dummy_y = self.lb.fit_transform(self.label_list)return dummy_y# 使用信息熵进行分类def clf_play(self):
clfPlay = tree.DecisionTreeClassifier(criterion="entropy")
clfPlay = clfPlay.fit(self.feature_vectorization(), self.label_vectorization())return clfPlaydef visualize_model(self):
with open(r"./InformationGain.dot", "w") as f:
f = tree.export_graphviz(self.clfPlay, feature_names=self.vec.get_feature_names(), out_file=f)
tree.export_graphviz(self.clfPlay, feature_names=self.vec.get_feature_names(), out_file=sys.stdout)if __name__ == '__main__':
my_tree = MyTree()