|
1. SDS:简单动态字符串(simple dynamic string)
Redis没有直接使用C语言的字符串,而是自己构建了一种名为简单动态字符串类型,并将SDS用作Redis的默认字符串。
SDS的定义
struct sdshdr {
// buf 中已占用空间的长度
int len;
// buf 中剩余可用空间的长度
int free;
// 字节数组
char buf[];
};
SDS与C字符串的区别
- SDS获取字符串长度复杂度为O(1), C字符串获取字符串长度复杂度为O(N);
因为C字符串获取字符串并不记录自身长度,程序必须遍历整个字符串对每个字符串计数。这个操作的复杂度为O(N)
SDS在len属性中记录了SDS本身长度,所以获取字符串长度复杂度为O(1)
- API是安全的,不会造成缓冲区溢出;
C字符串不记录自身长度,如果忘了给字符串扩容执行字符串拼接就会造成溢出
SDS拼接字符串之前会先通过free字段检测剩余空间能否满足需求,不能满足需求的就会扩容。
- 减少修改字符串带来的内存重分配次数;
C字符串底层总是一个N+1个字符数组,所以每次增长或缩短一个字符串,程序总要对这个C字符串进行一次内存重分配。
SDS实现空间预分配和惰性空间释放两种优化策略.
- 二进制安全
C字符串只能保存文本数据
SDS可以保存文本或者二进制数据
** 2. 链表 **
Redis的List(列表)和发布订阅,慢查询,监视器等功能都用到了链表
链表节点实现 adlist.h/listNode结构表示
// listNode 双端链表节点
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
该链表为双向链表,由多个listNode结点组成的链表结构图如下:

链表实现 adlist.h/list结构表示
// list 双端链表
typedef struct list { // 在c语言中,用结构体的方式来模拟对象是一种常见的手法
// 表头节点
listNode *head;
// 表尾节点
listNode *tail;
// 节点值复制函数
void *(*dup)(void *ptr);
// 节点值释放函数
void(*free)(void *ptr);
// 节点值对比函数
int(*match)(void *ptr, void *key);
// 链表所包含的节点数量
unsigned long len;
} list;
例:由一个list结构和三个listNode结构组成的链表
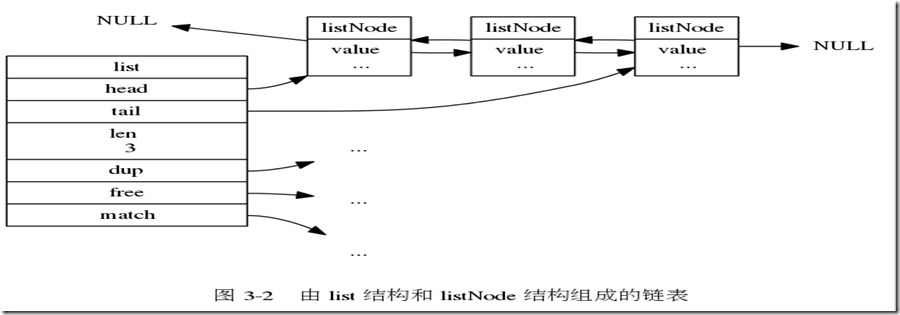
链表提供表头指针head,表尾指针tail,以及链表长度计数器len,和封装了3个内置函数
1.dup函数:复制链表结点所保存的值
2.free函数:释放链表结点所保存的值
3.match函数:对比链表结点所保存的值和另一个输入值是否相等
这三个函数是用于实现多态链表所需的类型特定函数。
Redis链表实现特征总结
1.双端:获取某个结点的前驱和后继结点都是O(1)
2.无环:表头的prev指针和表尾的next指针都指向NULL,对链表的访问都是以NULL为终点
3.带表头指针和表尾指针:获取表头和表尾的复杂度都是O(1)
4.带链表长度计数器:len属性记录,获取链表长度O(1)
5.多态:链表结点使用void*指针来保存结点的值,并且可以通过链表结构的三个函数为结点值设置类型特定函数,所以链表可以保存各种不同类型的值
-
字典
- 字典的实现
哈希节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对。
// dictEntry 哈希表节点
typedef struct dictEntry {
// 键
void *key;
// 值
union {//值v的类型可以是以下三种类型
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;
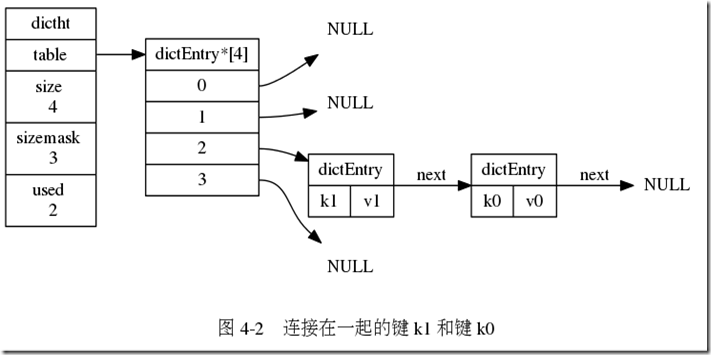
Redis字典使用哈希表有dictht.h/dictht结构定义
typedef struct dictht {
// 哈希表数组, 每个元素都是一条链表
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
// dict 字典
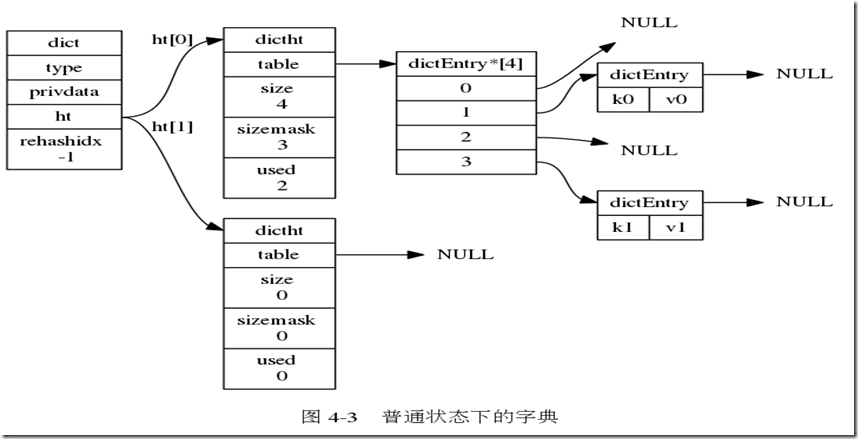
typedef struct dict {
// 类型特定函数
dictType *type; // type里面主要记录了一系列的函数,可以说是规定了一系列的接口
// 私有数据
void *privdata; // privdata保存了需要传递给那些类型特定函数的可选参数
//两张哈希表
dictht ht[2];//便于渐进式rehash
//rehash 索引,并没有rehash时,值为 -1
int rehashidx;
//目前正在运行的安全迭代器的数量
int iterators;
} dict;
* type 属性是一个指向dictType结构的指针,每个dictType结构保存了一族用于操作特定类型键值对的函数,Redis为用途不同的字典设置不同的类型特定函数。
* privdata 属性则保存了需要传递给那些类型特定函数的可选参数。
* ht是一个包含两个项的数组,数组每个项都是一个dictht哈希表,一般情况下只使用ht[0]哈希表,ht[1]只会对ht[0]哈希表进行rehash时使用。
* rehashidx它记录了rehash目前的进度,如果目前没有进行rehash,那么他的值为-1.
// dictType 用于操作字典类型函数
typedef struct dictType {
// 计算哈希值的函数
unsigned int(*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int(*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void(*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void(*valDestructor)(void *privdata, void *obj);
} dictType;
-
哈希算法
使用字典类型设置的哈希函数击视键key的哈希值
int hash = dict->type->hashFunction(key)
使用哈希表的sizemask的属性和哈希值计算出索引值
index = hash & dict->ht[0].sizemask;
使用哈希表节点next指针构成单向链表解决哈希冲突。
-
扩展和收缩哈希表的恭祝通过执行rehash操作来完成步骤如下
如果执行的是扩展操作,那么扩展ht[1]的大小为第一个大于等于ht[0].used*2的2的n此幂
如果执行的是收缩操作,那么收缩ht[1]的大小为第一个大于等于ht[0].used的2的n此幂
将保存在ht[0]中的所有键值对rehash到ht[1]上面:rehash指的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指点位置。
当ht[0]包含的所有键值对都迁移到ht[1]之后,释放ht[0],将ht[1]设置为ht[0],并在ht[1]重新创建一个空哈希表,为下一次rehash做准备。
当以下条件中的任意一个被满足时,程序会自动开始对哈希表进行扩展操作
1)服务器目前没有执行BGSAVE命令或者BGREWRITEOF命令,并且哈希表的负载因子大于等于1.
2)服务器目前正在执行BGSAVE命令或者BGREWRITEOF命令,并且哈希表的负载因子大于等于5.
3) 哈希表的负载因子可以通过公式:load_factor = ht[0].used / ht[0].size;
4) 哈希表的负载因子小于0.1时,自动执行哈希表收缩操作;
-
如果哈希表中有成千上万个键值对,那么要一次性rehash到ht[1]的话,可能会导致服务器一段时间内停止服务。为了避免rehash对服务器性能影响,服务器二十分多次,渐进性的将ht[0]里面的键值对渐进性的rehash。详细步骤:
1)为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表。
2)在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始。
3) 在rehash进行期间,每次对字典执行添加,删除,查找或者更新操作时,程序除了执行指定的操作外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],完成顺带操作后,程序将rehashidx属性的值加一.
4) 随着字典操作的不断执行,最终在某个时间点,ht[0]的所有键值对会被rehash至ht[1]。这是将rehashidx设置为-1.表示rehash操作已执行完。
|
















