|
1、LISTENING状态 FTP服务启动后首先处于侦听(LISTENING)状态。 2、ESTABLISHED状态 ESTABLISHED的意思是建立连接。表示两台机器正在通信。 3、CLOSE_WAIT 对方主动关闭连接或者网络异常导致连接中断,这时我方的状态会变成CLOSE_WAIT 此时我方要调用close()来使得连接正确关闭 4、TIME_WAIT 我方主动调用close()断开连接,收到对方确认后状态变为TIME_WAIT。TCP协议规定TIME_WAIT状态会一直持续2MSL(即两倍的分 段最大生存期),以此来确保旧的连接状态不会对新连接产生影响。处于TIME_WAIT状态的连接占用的资源不会被内核释放,所以作为服务器,在可能的情 况下,尽量不要主动断开连接,以减少TIME_WAIT状态造成的资源浪费。 目前有一种避免TIME_WAIT资源浪费的方法,就是关闭socket的LINGER选项。但这种做法是TCP协议不推荐使用的,在某些情况下这个操作可能会带来错误。 5、SYN_SENT状态 SYN_SENT状态表示请求连接,当你要访问其它的计算机的服务时首先要发个同步信号给该端口,此时状态为SYN_SENT,如果连接成功了就变为 ESTABLISHED,此时SYN_SENT状态非常短暂。但如果发现SYN_SENT非常多且在向不同的机器发出,那你的机器可能中了冲击波或震荡波 之类的病毒了。这类病毒为了感染别的计算机,它就要扫描别的计算机,在扫描的过程中对每个要扫描的计算机都要发出了同步请求,这也是出现许多 SYN_SENT的原因。 根据TCP协议定义的3次握手断开连接规定,发起socket主动关闭的一方 socket将进入TIME_WAIT状态,TIME_WAIT状态将持续2个MSL(Max Segment Lifetime),在Windows下默认为4分钟,即240秒,TIME_WAIT状态下的socket不能被回收使用. 具体现象是对于一个处理大量短连接的服务器,如果是由服务器主动关闭客户端的连接,将导致服务器端存在大量的处于TIME_WAIT状态的socket, 甚至比处于Established状态下的socket多的多,严重影响服务器的处理能力,甚至耗尽可用的socket,停止服务. TIME_WAIT是TCP协议用以保证被重新分配的socket不会受到之前残留的延迟重发报文影响的机制,是必要的逻辑保证. HttpClient连接池抛出大量ConnectionPoolTimeoutException: Timeout waiting for connection异常排查 今天解决了一个HttpClient的异常,汗啊,一个HttpClient使用稍有不慎都会是毁灭级别的啊。 这里有之前因为route配置不当导致服务器异常的一个处理:http://blog.csdn.net/shootyou/article/details/6415248 里面的HttpConnectionManager实现就是我在这里使用的实现。 简单来说CLOSE_WAIT数目过大是由于被动关闭连接处理不当导致的。 我说一个场景,服务器A会去请求服务器B上面的apache获取文件资源,正常情况下,如果请求成功,那么在抓取完资源后服务器A会主动发出关闭连接的请求,这个时候就是主动关闭连接,连接状态我们可以看到是TIME_WAIT。如果一旦发生异常呢?假设请求的资源服务器B上并不存在,那么这个时候就会由服务器B发出关闭连接的请求,服务器A就是被动的关闭了连接,如果服务器A被动关闭连接之后自己并没有释放连接,那就会造成CLOSE_WAIT的状态了。 一、“多半是程序的原因”?这个还是交给程序猿吧 二、linux 下 CLOSE_WAIT过多的解决方法 情景描述:系统产生大量“Too many open files” 原因分析:在服务器与客户端通信过程中,因服务器发生了socket未关导致的closed_wait发生,致使监听port打开的句柄数到了1024个,且均处于close_wait的状态,最终造成配置的port被占满出现“Too many open files”,无法再进行通信。 close_wait状态出现的原因是被动关闭方未关闭socket造成 解决办法:有两种措施可行 一、解决: 原因是因为调用ServerSocket类的accept()方法和Socket输入流的read()方法时会引起线程阻塞,所以应该用setSoTimeout()方法设置超时(缺省的设置是0,即超时永远不会发生);超时的判断是累计式的,一次设置后,每次调用引起的阻塞时间都从该值中扣除,直至另一次超时设置或有超时异常抛出。 比如,某种服务需要三次调用read(),超时设置为1分钟,那么如果某次服务三次read()调用的总时间超过1分钟就会有异常抛出,如果要在同一个Socket上反复进行这种服务,就要在每次服务之前设置一次超时。 二、规避: 调整系统参数,包括句柄相关参数和TCP/IP的参数; 注意: /proc/sys/fs/file-max 是整个系统可以打开的文件数的限制,由sysctl.conf控制; ulimit修改的是当前shell和它的子进程可以打开的文件数的限制,由limits.conf控制; lsof是列出系统所占用的资源,但是这些资源不一定会占用打开文件号的;比如:共享内存,信号量,消息队列,内存映射等,虽然占用了这些资源,但不占用打开文件号; 因此,需要调整的是当前用户的子进程打开的文件数的限制,即limits.conf文件的配置; 如果cat /proc/sys/fs/file-max值为65536或甚至更大,不需要修改该值; 若ulimit -a ;其open files参数的值小于4096(默认是1024), 则采用如下方法修改open files参数值为8192;方法如下: 1.使用root登陆,修改文件/etc/security/limits.conf vim /etc/security/limits.conf 添加 xxx - nofile 8192 xxx 是一个用户,如果是想所有用户生效的话换成 * ,设置的数值与硬件配置有关,别设置太大了。 #<domain> <type> <item> <value> * soft nofile 8192 * hard nofile 8192 #所有的用户每个进程可以使用8192个文件描述符。 2.使这些限制生效 确定文件/etc/pam.d/login 和/etc/pam.d/sshd包含如下行: session required pam_limits.so 然后用户重新登陆一下即可生效。 3. 在bash下可以使用ulimit -a 参看是否已经修改: 一、 修改方法:(暂时生效,重新启动服务器后,会还原成默认值) sysctl -w net.ipv4.tcp_keepalive_time=600 sysctl -w net.ipv4.tcp_keepalive_probes=2 sysctl -w net.ipv4.tcp_keepalive_intvl=2 注意:Linux的内核参数调整的是否合理要注意观察,看业务高峰时候效果如何。 二、 若做如上修改后,可起作用;则做如下修改以便永久生效。 vi /etc/sysctl.conf 若配置文件中不存在如下信息,则添加: net.ipv4.tcp_keepalive_time = 1800 net.ipv4.tcp_keepalive_probes = 3 net.ipv4.tcp_keepalive_intvl = 15 编辑完 /etc/sysctl.conf,要重启network 才会生效 /etc/rc.d/init.d/network restart 然后,执行sysctl命令使修改生效,基本上就算完成了。 修改原因: 当客户端因为某种原因先于服务端发出了FIN信号,就会导致服务端被动关闭,若服务端不主动关闭socket发FIN给Client,此时服务端Socket会处于CLOSE_WAIT状态(而不是LAST_ACK状态)。通常来说,一个CLOSE_WAIT会维持至少2个小时的时间(系统默认超时时间的是7200秒,也就是2小时)。如果服务端程序因某个原因导致系统造成一堆CLOSE_WAIT消耗资源,那么通常是等不到释放那一刻,系统就已崩溃。因此,解决这个问题的方法还可以通过修改TCP/IP的参数来缩短这个时间,于是修改tcp_keepalive_*系列参数: tcp_keepalive_time: /proc/sys/net/ipv4/tcp_keepalive_time 点击打开链接 INTEGER,默认值是7200(2小时) 当keepalive打开的情况下,TCP发送keepalive消息的频率。建议修改值为1800秒。 tcp_keepalive_probes:INTEGER /proc/sys/net/ipv4/tcp_keepalive_probes INTEGER,默认值是9 TCP发送keepalive探测以确定该连接已经断开的次数。(注意:保持连接仅在SO_KEEPALIVE套接字选项被打开是才发送.次数默认不需要修改,当然根据情形也可以适当地缩短此值.设置为5比较合适) tcp_keepalive_intvl:INTEGER /proc/sys/net/ipv4/tcp_keepalive_intvl INTEGER,默认值为75 当探测没有确认时,重新发送探测的频度。探测消息发送的频率(在认定连接失效之前,发送多少个TCP的keepalive探测包)。乘以tcp_keepalive_probes就得到对于从开始探测以来没有响应的连接杀除的时间。默认值为75秒,也就是没有活动的连接将在大约11分钟以后将被丢弃。(对于普通应用来说,这个值有一些偏大,可以根据需要改小.特别是web类服务器需要改小该值,15是个比较合适的值) 1. 系统不再出现“Too many open files”报错现象。 2. 处于TIME_WAIT状态的sockets不会激长。 在 Linux 上可用以下语句看了一下服务器的TCP状态(连接状态数量统计): netstat -n| awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'服务器TIME_WAIT和CLOSE_WAIT详解和解决办法 在服务器的日常维护过程中,会经常用到下面的命令:
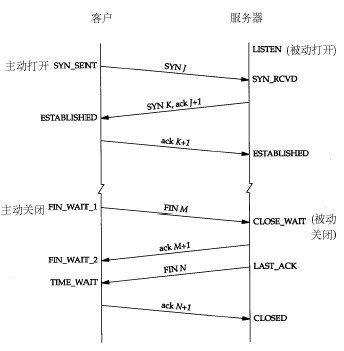
它会显示例如下面的信息: TIME_WAIT 814 常用的三个状态是:ESTABLISHED 表示正在通信,TIME_WAIT 表示主动关闭,CLOSE_WAIT 表示被动关闭。 具体每种状态什么意思,其实无需多说,看看下面这种图就明白了,注意这里提到的服务器应该是业务请求接受处理的一方:
这么多状态不用都记住,只要了解到我上面提到的最常见的三种状态的意义就可以了。一般不到万不得已的情况也不会去查看网络状态,如果服务器出了异常,百分之八九十都是下面两种情况: 1.服务器保持了大量TIME_WAIT状态 2.服务器保持了大量CLOSE_WAIT状态 因为linux分配给一个用户的文件句柄是有限的(可以参考:http://blog.csdn.net/shootyou/article/details/6579139),而TIME_WAIT和CLOSE_WAIT两种状态如果一直被保持,那么意味着对应数目的通道就一直被占着,而且是“占着茅坑不使劲”,一旦达到句柄数上限,新的请求就无法被处理了,接着就是大量Too Many Open Files异常,tomcat崩溃。。。 下 面来讨论下这两种情况的处理方法,网上有很多资料把这两种情况的处理方法混为一谈,以为优化系统内核参数就可以解决问题,其实是不恰当的,优化系统内核参 数解决TIME_WAIT可能很容易,但是应对CLOSE_WAIT的情况还是需要从程序本身出发。现在来分别说说这两种情况的处理方法: 1.服务器保持了大量TIME_WAIT状态 这种情况比较常见,一些爬虫服务器或者WEB服务器(如果网管在安装的时候没有做内核参数优化的话)上经常会遇到这个问题,这个问题是怎么产生的呢? 从 上面的示意图可以看得出来,TIME_WAIT是主动关闭连接的一方保持的状态,对于爬虫服务器来说他本身就是“客户端”,在完成一个爬取任务之后,他就 会发起主动关闭连接,从而进入TIME_WAIT的状态,然后在保持这个状态2MSL(max segment lifetime)时间之后,彻底关闭回收资源。为什么要这么做?明明就已经主动关闭连接了为啥还要保持资源一段时间呢?这个是TCP/IP的设计者规定 的,主要出于以下两个方面的考虑: 1.防止上一次连接中的包,迷路后重新出现,影响新连接(经过2MSL,上一次连接中所有的重复包都会消失) 关于MSL引用下面一段话:
再引用网络资源的一段话:
也就是说HTTP的交互跟上面画的那个图是不一样的,关闭连接的不是客户端,而是服务器,所以web服务器也是会出现大量的TIME_WAIT的情况的。 现在来说如何来解决这个问题。 解决思路很简单,就是让服务器能够快速回收和重用那些TIME_WAIT的资源。 下面来看一下我们网管对/etc/sysctl.conf文件的修改:
修改完之后执行/sbin/sysctl -p让参数生效。 这里头主要注意到的是net.ipv4.tcp_tw_reuse net.ipv4.tcp_tw_recycle net.ipv4.tcp_fin_timeout net.ipv4.tcp_keepalive_* 这几个参数。 net.ipv4.tcp_tw_reuse和net.ipv4.tcp_tw_recycle的开启都是为了回收处于TIME_WAIT状态的资源。 net.ipv4.tcp_fin_timeout这个时间可以减少在异常情况下服务器从FIN-WAIT-2转到TIME_WAIT的时间。 net.ipv4.tcp_keepalive_*一系列参数,是用来设置服务器检测连接存活的相关配置。 关于keepalive的用途可以参考:http://hi.baidu.com/tantea/blog/item/580b9d0218f981793812bb7b.html 2.服务器保持了大量CLOSE_WAIT状态 休息一下,喘口气,一开始只是打算说说TIME_WAIT和CLOSE_WAIT的区别,没想到越挖越深,这也是写博客总结的好处,总可以有意外的收获。 TIME_WAIT状态可以通过优化服务器参数得到解决,因为发生TIME_WAIT的情况是服务器自己可控的,要么就是对方连接的异常,要么就是自己没有迅速回收资源,总之不是由于自己程序错误导致的。 但 是CLOSE_WAIT就不一样了,从上面的图可以看出来,如果一直保持在CLOSE_WAIT状态,那么只有一种情况,就是在对方关闭连接之后服务器程 序自己没有进一步发出ack信号。换句话说,就是在对方连接关闭之后,程序里没有检测到,或者程序压根就忘记了这个时候需要关闭连接,于是这个资源就一直 被程序占着。个人觉得这种情况,通过服务器内核参数也没办法解决,服务器对于程序抢占的资源没有主动回收的权利,除非终止程序运行。 如果你使用的是HttpClient并且你遇到了大量CLOSE_WAIT的情况,那么这篇日志也许对你有用:http://blog.csdn.net/shootyou/article/details/6615051 在那边日志里头我举了个场景,来说明CLOSE_WAIT和TIME_WAIT的区别,这里重新描述一下: 服 务器A是一台爬虫服务器,它使用简单的HttpClient去请求资源服务器B上面的apache获取文件资源,正常情况下,如果请求成功,那么在抓取完 资源后,服务器A会主动发出关闭连接的请求,这个时候就是主动关闭连接,服务器A的连接状态我们可以看到是TIME_WAIT。如果一旦发生异常呢?假设 请求的资源服务器B上并不存在,那么这个时候就会由服务器B发出关闭连接的请求,服务器A就是被动的关闭了连接,如果服务器A被动关闭连接之后程序员忘了 让HttpClient释放连接,那就会造成CLOSE_WAIT的状态了。 所以如果将大量CLOSE_WAIT的解决办法总结为一句话那就是:查代码。因为问题出在服务器程序里头啊。 参考资料: 1.windows下的TIME_WAIT的处理可以参加这位大侠的日志:http://blog./post/2010/11/17/How-to-deal-with-TIME_WAIT-problem-under-Windows.aspx 2.WebSphere的服务器优化有一定参考价值:http://publib.boulder.ibm.com/infocenter/wasinfo/v6r0/index.jsp?topic=/com.ibm.websphere.express.doc/info/exp/ae/tprf_tunelinux.html 3.各种内核参数的含义:http://haka./blog/BlogTopic/32309.htm 4.linux服务器历险之sysctl优化linux网络:http://blog.csdn.net/chinalinuxzend/article/details/1792184 |
|
|