|
(1)、执行ceph-deploy install ceph01 ceph02 ceph03时报错
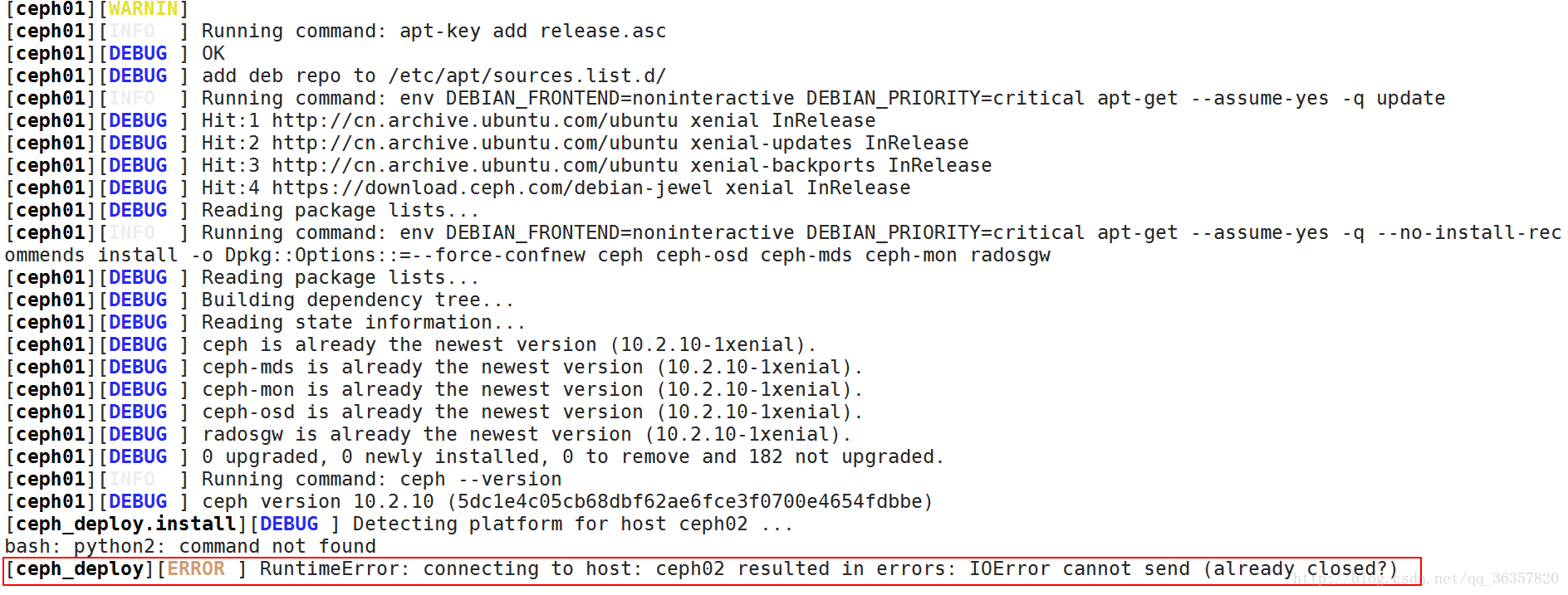
解决办法:
经过查询方知道是由于网络慢的原因导致的
可现在ceph02、ceph03节点安装上ceph
apt install -y ceph
再执行上述步骤
问题解决
(2)、HEALTH_WARN too few PGs per OSD (21 < min 30)
root@ceph01:/mnt/mycluster# ceph -s
cluster 1838d346-9ecc-4b06-a5f9-cc086a7e7eec
health HEALTH_WARN
too few PGs per OSD (21 < min 30)
monmap e1: 3 mons at {ceph01=192.168.93.14:6789/0,ceph02=192.168.93.15:6789/0,ceph03=192.168.93.11:6789/0}
election epoch 4, quorum 0,1,2 ceph03,ceph01,ceph02
osdmap e43: 9 osds: 9 up, 9 in
flags sortbitwise,require_jewel_osds
pgmap v109: 64 pgs, 1 pools, 0 bytes data, 0 objects
46380 MB used, 134 GB / 179 GB avail
64 active+clean
由于是新配置的集群,只有一个pool
root@ceph01:/mnt/mycluster# ceph osd lspools
0 rbd,
查看rbd pool的PGS
root@ceph01:/mnt/mycluster# ceph osd pool get rbd pg_num
pg_num: 64
pgs为64,因为是3副本的配置,所以当有9个osd的时候,每个osd上均分了64/9 *3=21个pgs,也就是出现了如上的错误 小于最小配置30个
解决办法:修改默认pool rbd的pgs
root@ceph01:/mnt/mycluster# ceph osd pool set rbd pg_num 128
set pool 0 pg_num to 128
root@ceph01:/mnt/mycluster# ceph -s
cluster 1838d346-9ecc-4b06-a5f9-cc086a7e7eec
health HEALTH_WARN
pool rbd pg_num 128 > pgp_num 64
monmap e1: 3 mons at {ceph01=192.168.93.14:6789/0,ceph02=192.168.93.15:6789/0,ceph03=192.168.93.11:6789/0}
election epoch 4, quorum 0,1,2 ceph03,ceph01,ceph02
osdmap e45: 9 osds: 9 up, 9 in
flags sortbitwise,require_jewel_osds
pgmap v127: 128 pgs, 1 pools, 0 bytes data, 0 objects
46382 MB used, 134 GB / 179 GB avail
128 active+clean
发现需要把pgp_num也一并修改,默认两个pg_num和pgp_num一样大小均为64,此处也将两个的值都设为128
root@ceph01:/mnt/mycluster# ceph osd pool get rbd pgp_num
pgp_num: 64
root@ceph01:/mnt/mycluster# ceph osd pool set rbd pgp_num 128
set pool 0 pgp_num to 128
最后查看集群状态,显示为OK,错误解决:
root@ceph01:/mnt/mycluster# ceph -s
cluster 1838d346-9ecc-4b06-a5f9-cc086a7e7eec
health HEALTH_OK
monmap e1: 3 mons at {ceph01=192.168.93.14:6789/0,ceph02=192.168.93.15:6789/0,ceph03=192.168.93.11:6789/0}
election epoch 4, quorum 0,1,2 ceph03,ceph01,ceph02
osdmap e47: 9 osds: 9 up, 9 in
flags sortbitwise,require_jewel_osds
pgmap v142: 128 pgs, 1 pools, 0 bytes data, 0 objects
46385 MB used, 134 GB / 179 GB avail
128 active+clean
(3)、HEALTH_WARN clock skew detected on mon.ceph02
root@ceph01:/var/lib/ceph/osd/ceph-2/current# ceph -s
cluster 1838d346-9ecc-4b06-a5f9-cc086a7e7eec
health HEALTH_WARN
clock skew detected on mon.ceph02
Monitor clock skew detected
monmap e1: 3 mons at {ceph01=192.168.93.14:6789/0,ceph02=192.168.93.15:6789/0,ceph03=192.168.93.11:6789/0}
election epoch 4, quorum 0,1,2 ceph03,ceph01,ceph02
osdmap e47: 9 osds: 9 up, 9 in
flags sortbitwise,require_jewel_osds
pgmap v151: 128 pgs, 1 pools, 0 bytes data, 0 objects
46384 MB used, 134 GB / 179 GB avail
128 active+clean
这是由于集群的时间不一致,同步一下时间ok
root@ceph01:/var/lib/ceph/osd/ceph-2/current# ntpq -p
remote refid st t when poll reach delay offset jitter
==============================================================================
0.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
1.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
2.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
3.ubuntu.pool.n .POOL. 16 p - 64 0 0.000 0.000 0.000
ntp.ubuntu.com .POOL. 16 p - 64 0 0.000 0.000 0.000
+ns.ustc.edu.cn 202.118.1.81 3 u 526 256 376 31.628 -10.231 24.584
*dns1.synet.edu. 202.118.1.47 2 u 3 256 177 38.342 -19.102 13.452
-85.199.214.100 .GPS. 1 u 1 64 377 225.205 24.569 3.503
+202.118.1.130 202.118.1.46 2 u 246 256 377 37.415 -20.863 17.250
-101.236.4.18 202.118.1.46 2 u 230 256 377 3.861 1.357 7.409
|
















