|
#零、前言
前段时间看到文章【1】和【2】,大概了解了面部合成的基本原理。这两天空下来了,于是参考【3】自己实现了下。虽然【1】和【2】已经讲的很清楚了,但是有一些细节没有提到。所以我在这里记录一下实现的过程中以及一些小细节。
#一、什么是面部合成?
这里的面部合成指的的是把一张脸逐渐的变化成另外一张脸。图1展示了从詹姆斯渐变到科比的过程。其实如果把这些图片合成视频的话效果会更好。但是我不知道在这里怎么添加视频,所以就没弄了。
         
图 1. 勒布朗詹姆斯到科比的渐变。第一排第一张为詹姆斯原图,第二排最后为科比原图。从第一排到第二排为渐变过程。
#二 、主要步骤
面部合成的原理就是利用给定的两张图片  和 生成 张从渐变到的过度图片 。这过度图片生成的原理是一样的,通过一个参数来控制混合的程度。 和 生成 张从渐变到的过度图片 。这过度图片生成的原理是一样的,通过一个参数来控制混合的程度。
(1)
当接近0时,看起来比较像 ,当接近1时,看起来比较像。当然啦,这个公式只是一个大概的意思。具体来说一共分为如下几部:1. 检测人脸关键点。2. 三角剖分。3. 图像变形。下面就从这3点展开来说。
#1. 人脸关键点定位
给定两张图片,每张图片里面有一个人脸。我们要做的第一步就是分别从这两张图片中检测出人脸,并在定位出人脸关键点。人脸一共有68个关键点,分布如图2所示。不过我的研究方向不是搞人脸的,所以这个是做这个项目的时候才去了解的。如果有什么偏差,还望指正。

图 2. 人脸关键点分布说明图。
人脸检测和关键点定位可以使用Dlib[4]这个库来完成。Dlib是一个开源的使用现代C++技术编写的跨平台的通用库。它包含很多的模块,例如算法,线性代数,贝叶斯网络,机器学习,图像处理等等。其中图像处理模块就有人脸检测和关键点定位的函数。关于人脸检测和关键点定位的具体原理在这里我就不讨论了(不了解。。。),下面说下具体怎么调用。
首先我们需要检测出图像中人脸的位置,所以需要一个人脸检测器。这只要直接定义一个Dilb中frontal_face_detector类的对象就可以了。
frontal_face_detector detector = get_frontal_face_detector();
有了这个检测器之后我们就可以检测人脸了。由于一张图片中可能有多个人脸,所以这里检测的结果是保存在一个vector容器里面的。vector里面的对象类型是rectangle,这个数据类型描述了人脸在图片中的位置。具体来说,这一步人脸检测的结果只是一个人脸边界框(face bounding box),人脸在被包含在方框中(图3)。而rectangle里面保存了这个方框的左上和右下点的坐标。
array2d<rgb_pixel> img;
load_image(img, "yxy.png");
std::vector<rectangle> dets = detector(img);

图 3. 人脸检测示意图。
检测出人脸之后,我们接下来要在人脸中定位关键点。首先我们需要一个关键点检测器(shape_predictor)。首先定义一个Dlib中的shape_predictor类的对象,然后用shape_predictor_68_face_landmarks.dat这个模型来初始化这个检测器。shape_predictor_68_face_landmarks.dat模型可以从 Dlib官网 中下载下来,然后放入你的工程文件里面。
shape_predictor sp;
deserialize("shape_predictor_68_face_landmarks.dat") >> sp;
有了这个关键点检测器之后,我们就可以检测人脸关键点了。这个检测器的输入是一副图片和一个人脸边界框。输出是一个shape对象。这个shape对象里面保存了检测到的68个人脸关键点的坐标。可以通过下面的方式把这些关键点的坐标保存到一个txt文件中。
full_object_detection shape = sp(img, dets[j]);
ofstream out("yxy.txt");
for (int i = 0; i < shape.num_parts(); ++i)
{
auto a= shape.part(i);
out<<a.x()<<" "<<a.y()<<" ";
}
 
图 4. 检测出的人脸关键点
最后检测出的关键点图4所示。注意图4中每幅图片我都手工加了8个点。分别是图片四个顶点和四条边的中点。加这些点是为了下一步能有更好的效果。
#2. 三角剖分
检测出了两幅图片中人脸的关键点之后,我们先求中间图片 关键点的坐标。这是通过公式1来计算的。具体来说就是我们要在中间图片 定位72个关键点的坐标。每一个关键点的坐标是通过给定的两幅图片 和 中对应的关键点坐标加权得到的。
std::vector<Point2f> points1 = readPoints("lbj.txt"); //詹姆斯关键点
std::vector<Point2f> points2 = readPoints("kb.txt"); //科比关键点
std::vector<Point2f> points; //中间图片关键点
for (int i = 0; i < points1.size(); i++)
{
float x, y;
x = (1 - alpha) * points1[i].x + alpha * points2[i].x;
y = (1 - alpha) * points1[i].y + alpha * points2[i].y;
points.push_back(Point2f(x, y));
}
求出了中间图片的关键点坐标之后,我们对这些点进行三角剖分。关于三角剖分的具体解释可以参考【5】。简单来说就是返回一堆三角形。每个三角形的顶点都是由那些关键点组成的。这样整个平面就被剖分成了很多小的三角形。我们可以针对每一个小三角形进行操作。在opencv中,三角剖分的类为Subdiv2D。在定义这个类的对象之前,我们需要先定义一个Rect类的对象。这里的Rect与前面提到的Dlib中的rectangle类似。都是表示图像中的一个方框区域。只不过这里的Rect里面保存的是方框的左上角坐标以及方框的长和宽。所以这里我们定义一个与输入图像同样大小的Rect对象,然后用这个对象去初始化一个Subdiv2D对象subdiv。然后我们把中间图像的关键点加入到subdiv中。最后我们会得到一些六元组,每个六元组包括一个三角形的三个顶点的坐标(x,y)。
Size size = img1.size();
Rect rect(0, 0, size.width, size.height);
Subdiv2D subdiv(rect);
for (vector<Point2f>::iterator it = points.begin(); it != points.end(); it++)
subdiv.insert(*it);
std::vector<Vec6f> triangleList;
subdiv.getTriangleList(triangleList);
如图5(3)所示,我们通过三角剖分把中间图片分成了很多的小三角形。我们还需要把图片 和 也剖分成跟中间图片一样的三角形。也就是说中哪三个点构成一个三角形,那么 和 中对应的那三个点也构成一个三角形。这就需要构成一个三角形的三个顶点的索引。然而我们只有那三个顶点的坐标。所以我们需要把那些六元组里面的关键点坐标转换成关键点的索引。下面这段代码是【1】的作者提供的一种方法。这个方法的做法是把六元组中的三个点的坐标分别与所有的关键点坐标进行匹配。当两个点之间的距离小于1时认为是同一个点。当然这是一个比较笨的方法,其实opencv如果在Subdiv2D里面的数据结构里加一个点的索引项的话那就非常方便了。(不知道是不是本来就有的,只是我没找到。。。如果是这样的话求告知。。)。最后我们会得到类似图5(1)中的三元组。每一个三元组对应这一个三角形的顶点索引。比如说第一行[38 40 37]表示第一个三角形是由第38,40,37个关键点构成的。有了这些索引后,我们就可以把 和 也进行相应的三角剖分,如图5 (2)(4)所示。这样这三张图片中的三角形是一一对应的。
for (size_t i = 0; i < triangleList.size(); ++i)
{
Vec6f t = triangleList[i];
pt[0] = Point2f(t[0], t[1]);
pt[1] = Point2f(t[2], t[3]);
pt[2] = Point2f(t[4], t[5]);
if (rect.contains(pt[0]) && rect.contains(pt[1]) && rect.contains(pt[2]))
{
int count = 0;
for (int j = 0; j < 3; ++j)
for (size_t k = 0; k < points.size(); k++)
if (abs(pt[j].x - points[k].x) < 1.0 && abs(pt[j].y - points[k].y) < 1.0)
{
ind[j] = k;
count++;
}
if (count == 3)
delaunayTri.push_back(ind);
}
}
 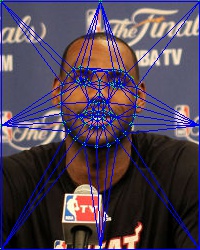 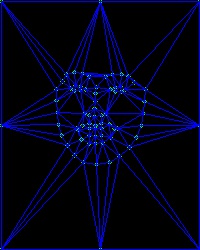 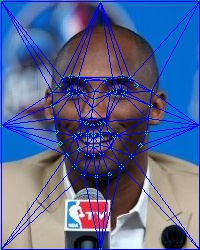
图 5. 三角剖分结果
#**3. 图像变形**
把输入的两幅图像以及要求的中间图像都三角剖分之后。我们接下来要做的是把中间图像上的小三角形一个一个的填满,然后得到最终的图像(图 6)。
接下来我们描述中间图像上的一个小三角形求得的过程。我们选定中间图像上的一个三角形,然后选定上对应的三角形。求出上的三角形中的像素到上的三角形中的像素的仿射变换。仿射变换满足下面的公式。其中左边为上三角形中的像素点的齐次坐标,右边为上三角形中的像素点的齐次坐标。中间为仿射变换矩阵。
(2)
求出仿射变换的参数后,我们把上三角形中的每一个像素点按照这个公式投影到上去,这样就得到了中选定的三角形区域的像素值。
以上这个求仿射变换和进行像素投影这两个步骤可以直接调用opencv中的函数applyAffineTransform来完成。但是applyAffineTransform的输入要求是一个方形区域而不是三角形区域。所以我们先boundingRect这个函数算出三角形的边界框(bounding box),对边界框内所有像素点进行仿射投影。同时用fillConvexPoly函数生成一个三角形的mask。也就是说生成一张三角形边界框大小的图片,这个图片中三角形区域像素值是1,其余区域像素值是0。投影完成后在用这个mask与投影结果进行逻辑与运算,从而获得三角形区域投影后的像素值。
以上只是求了中三角形到中选定三角形的投影。相应的,我们还要求图像中对应的三角形到中选定三角形的投影。方法和前面的一样。这样我们就得到了中选定三角形的两个变形图片。然后我们对这两个图片进行加权求的最终这个三角形的像素值。做法和公式(1)类似。具体代码如下:
void morphTriangle(Mat &img1, Mat &img2, Mat &img, std::vector<Point2f> &t1, std::vector<Point2f> &t2, std::vector<Point2f> &t, double alpha)
{
Rect r = boundingRect(t);
Rect r1 = boundingRect(t1);
Rect r2 = boundingRect(t2);
std::vector<Point2f> t1Rect, t2Rect, tRect;
std::vector<Point> tRectInt;
for (int i = 0; i < 3; ++i)
{
tRect.push_back(Point2f(t[i].x - r.x, t[i].y - r.y));
tRectInt.push_back(Point(t[i].x - r.x, t[i].y - r.y));
t1Rect.push_back(Point2f(t1[i].x - r1.x, t1[i].y - r1.y));
t2Rect.push_back(Point2f(t2[i].x - r2.x, t2[i].y - r2.y));
}
Mat mask = Mat::zeros(r.height, r.width, CV_32FC3);
fillConvexPoly(mask, tRectInt, Scalar(1.0, 1.0, 1.0), 16, 0);
Mat img1Rect, img2Rect;
img1(r1).copyTo(img1Rect);
img2(r2).copyTo(img2Rect);
Mat warpImage1 = Mat::zeros(r.height, r.width, img1Rect.type());
Mat warpImage2 = Mat::zeros(r.height, r.width, img2Rect.type());
applyAffineTransform(warpImage1, img1Rect, t1Rect, tRect);
applyAffineTransform(warpImage2, img2Rect, t2Rect, tRect);
Mat imgRect = (1.0 - alpha)*warpImage1 + alpha*warpImage2;
multiply(imgRect, mask, imgRect);
multiply(img(r), Scalar(1.0, 1.0, 1.0) - mask, img(r));
img(r) = img(r) + imgRect;
}
就这样一个三角形一个三角形的变换,我们就得到了一张完整的中间图像。然后通过变化的值(从0到1),从而得到一系列渐变的中间图像。最后将这些渐变图像写入到一个视频文件中就大功告成了!!
vector<Mat> pic;
pic.push_back(imread("lbj.png"));
string filename = "lbjkb";
for (double alpha = 0.1; alpha < 1; alpha = alpha + 0.1)
{
string framename = filename + to_string(alpha) + ".png";
pic.push_back(imread(framename));
}
pic.push_back(imread("kb.png"));
VideoWriter output_src("lbjkb.avi", CV_FOURCC('M', 'J', 'P', 'G'), 5, pic[0].size(), 1);
for (auto c : pic)
{
output_src<<c;
}
图 6. 图像变形示意图
#三、说明
- 以上所用到的部分图像来自网络,如有版权问题请联系我,谢谢。
- 这个项目的代码可以从【1】中下载。不过它里面默认关键点和索引对都是已知的。我自己的完整版代码见github:iamwx/FaceMorph
欢迎关注个人公众号!
微信交流群
参考资料:
- 【SATYA MALLICK】Face Morph Using OpenCV — C++ / Python
- 【大数据文摘】手把手:使用OpenCV进行面部合成— C++ / Python
- opencv github主页
- Dlib 库主页
- 【百度百科】Delaunay三角剖分算法
|
















