




一、逻辑回归
在 机器学习之线性回归 中,我们可使用梯度下降的方法得到一个映射函数 来去贴近样本点,这个函数是对连续值的一个预测。
而逻辑回归是解决分类问题的一个算法,我们可以通过这个算法得到一个映射函数 ,其中 为特征向量,, 为预测的结果。在逻辑回归这里,标签 为一个离散值。
二、判定边界
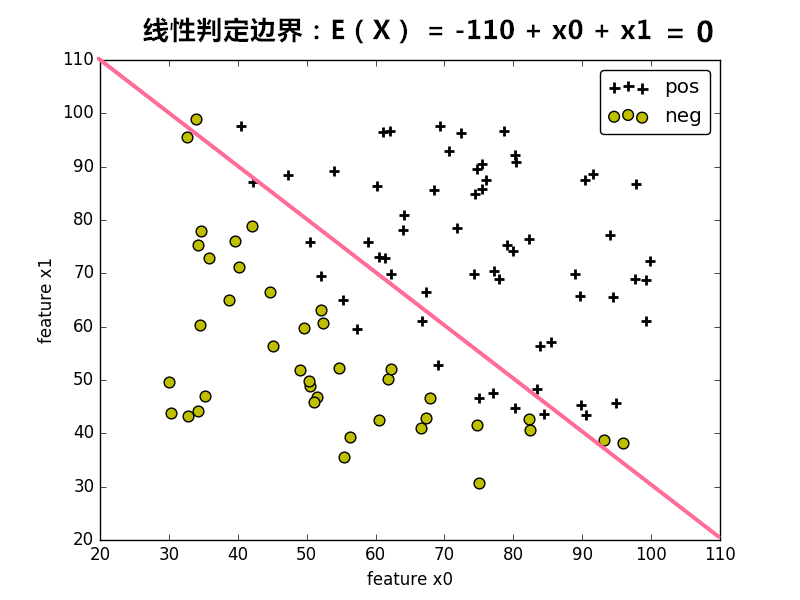
当将训练集的样本以其各个特征为坐标轴在图中进行绘制时,通常可以找到某一个 判定边界 去将样本点进行分类。例如:
线性判定边界:
非线性判定边界:
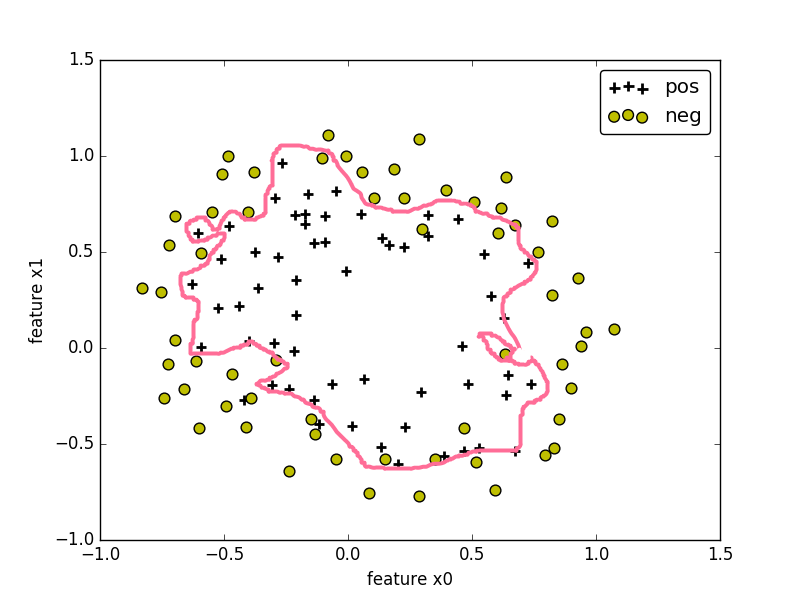
在图中,样本的标记类型有两种类型,一种为正样本,另一种为负样本,样本的特征 和 为坐标轴。根据样本的特征值,可将样本绘制在图上。
在图中,可找到某个 判定边界 来对不同标签的样本进行划分。根据这个判定边界,我们可以知道哪些样本是正样本,哪些样本为负样本。
因此我们可以通过学习得到一个方程 来表示 判定边界,即 判定边界 为 的点集。(可以看作是等高超平面)
其中 ,为保留 中的常数项,令特征向量 。
为使得我们的边界可以非线性化,对于特征 可以为特征的高次幂或相互的乘积。
对于位于判定边界上的样本,其特征向量 可使得 。因此,判定边界 是 满足 的特征向量 表示的点的集合。
三、二分类和sigmoid函数
在上面,可以通过找到一个判定边界来区别样本的标签,得到一个方程 来表示判定边界。
对于 二分类问题,即样本标签的类型只有两种类型。
当样本标记的类型只有两种时,其中一类的样本点在 判定边界的一边,其会有,而另一类的样本会在判定边界的另一边,会有 。
当样本点离 判定边界 越远时, 的绝对值越大于0,这时样本的标签是某种类型的概率会很大,可能会等于1;当样本点离 判定边界 越近时,的接近0,样本的标签是某种类型的概率会在0.5左右。
因此,我们可以将 函数 转换 为一种概率函数,通过概率来判断样本的标签是某一种类型的概率会是多少。而这种 转换 可以使用 sigmoid函数来实现 :
sigmoid函数图像如下:
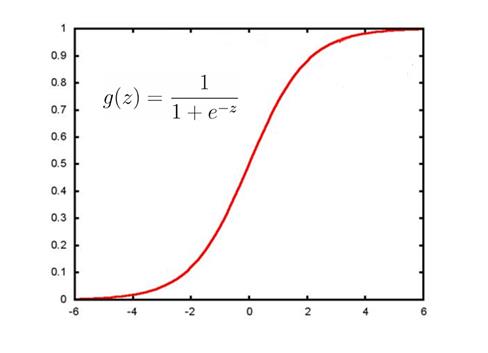
从sigmoid函数图像可看出:当z为0左右时,函数值为0.5左右;z越大于0时,函数值越大于0.5越收敛于1;z越小于0时,函数值越小于0.5越收敛于0。
因此,sigmoid函数可适用于在二分类问题中将 函数 转换为概率函数。
当时,样本标记的类型为某一类型的概率会大于0.5;当时,样本标记的类型为某一类型的概率会小于0.5;当 约等于 0时,样本标记的类型为某一类型的概率会在0.5左右。
在二分类问题中,可以找到逻辑回归函数,判定边界可看作 时的等高线。

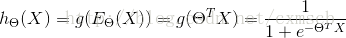
四、损失函数
由上面,找到了二分类问题中的一个逻辑回归函数 
在逻辑回归函数中,特征向量系数 是未知的,需要从样本中学习得来的。当从样本中学习得到一个特征向量系数 时,怎么知道它对应的 函数的预测能力会更好?判断更准确?因此,需要一个损失函数来表示逻辑回归函数 的好坏程度。
1. 定义
在二分类问题中,若用 的值 表示正样本的概率,且 ,需要的损失函数应该是这样的:
当样本标签的类型是正类型时,若该样本对应的 值为1时,即为正类型的概率为1,这时候损失函数值应为0;若该样本对应的 值为0.0001时,即为正样本的概率为0.0001,这时候损失函数值应该是一个很大的值。
当样本标记的类型是负类型时,若该样本对应的 值为0时,即为正样本的概率为0,这时损失函数值应为0;若该样本对应的 值为0.9999时,即为正样本的概率为0.9999,这时候损失函数值应该是一个很大的值。
因此二分类问题中,为满足这种需求,对于单个样本来说,其损失函数可以表示为:
( 的值表示正样本的概率)
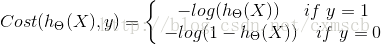
其中 y = 1 表示样本为正样本,y = 0 表示样本为负样本。
结合起来的写法:
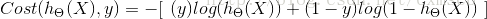
上式的代价函数也称作:交叉熵代价函数
对于训练集所有样本来说,共同造成的损失函数的均值 可以表示为:

将 Cost函数 代入 中:
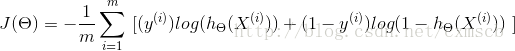
对于样本来说,其标记y为1 (正样本)或为 0(负样本),对于预测概率函数 来说,预测到样本为正样本的概率值在0到1之间。
2. 极大似然估计
上述的损失函数 也可以通过极大似然估计来求得:以 的值 表示正样本的概率,且以 y = 1 表示 正样本 ,y = 0 表示 负样本,则有:
合并上述两个式子则有:
对m个样本,求极大似然估计:
取对数似然估计:
对数似然取极值(极大值)时的 θ 取值便是我们想要的,因此需要对目标函数 进行最大化,即相当于 对 上述的 进行最小化:。
3. 正则化
同时,当预测概率函数 过拟合,会导致高次项的特征向量系数 过大(因为为 分清每个样本点的类型时会使得它足够的扭曲,这种扭曲通常由高次项的特征向量系数造成)。因此,为防止过拟合可以添加正则化项,即在损失函数的后面加个“尾巴”。
添加L2正则化项后的损失函数表示为:

五、最小化损失函数
在上面得到了 二分类问题 的逻辑回归的损失函数 。为达到不错的分类效果,需要对损失函数进行最小化。
与 线性回归 相类似的是,这里的损失函数也是一个凸函数,因此,可以通过梯度下降法来得到合适的特性系数向量Θ。
同样,上式中的a为学习率(下山步长)。将上式的偏导展开,可得:
非正则化的损失函数的偏导:
含正则化项的损失函数的偏导:
其中 λ 为正则化的强度。
同线性回归般,可以通过学习率a对特征系数向量中的元素不断进行迭代,直到元素值收敛到某一值即可,这时可以得到损失函数较小时的特征向量系数Θ。
六、从二分类过渡到多分类
在上面,我们主要使用逻辑回归解决二分类的问题,那对于多分类的问题,也可以用逻辑回归来解决?
1. one vs rest
由于概率函数 hΘ(X) 所表示的是样本标记为某一类型的概率,但可以将一对一(二分类)扩展为一对多(one vs rest):
将类型class1看作正样本,其他类型全部看作负样本,然后我们就可以得到样本标记类型为该类型的概率p1;
然后再将另外类型class2看作正样本,其他类型全部看作负样本,同理得到p2;
以此循环,我们可以得到该待预测样本的标记类型分别为类型class i时的概率pi,最后我们取pi中最大的那个概率对应的样本标记类型作为我们的待预测样本类型。
2. softmax函数
使用softmax函数构造模型解决多分类问题。
softmax回归分类器需要学习的函数为 :
其中 k 个 类别的个数 , 和 为 第 i 个 类别对应的 权重向量 和 偏移标量。
其中 可看作样本 X 的标签 为 第 j 个 类别的概率,且有 。
与 logistic回归 不同的是,softmax回归分类模型会有多个的输出,且输出个数 与 类别个数 相等,输出为样本 X 为各个类别的概率 ,最后对样本进行预测的类型为 概率最高 的那个类别。
我们需要通过学习得到 和 ,因此建立目标损失函数为:
上式的代价函数也称作:对数似然代价函数。
在二分类的情况下,对数似然代价函数 可以转化为 交叉熵代价函数。
其中 m 为训练集样本的个数,k 为 类别的个数, 为示性函数,当 为真时,函数值为 1 ,否则为 0 ,即 样本类别正确时,函数值才为 1 。
利用 对数的性质 ,将 损失函数 展开有:
继续展开:
通过 梯度下降法 最小化损失函数 和 链式偏导,使用 对 求偏导:
化简可得:
再次化简可有:
因此由 梯度下降法 进行迭代:
同理 通过梯度下降法最小化损失函数也可以得到 的最优值。
同逻辑回归一样,可以给损失函数加上正则化项。
3. 选择的方案
当标签类别之间是互斥时,适合选择softmax回归分类器 ;当标签类别之间不完全互斥时,适合选择建立多个独立的logistic回归分类器。
4. tensorflow代码示例:
- 使用softmax回归对sklearn中的digit手写数据进行分类







